추천 콘텐츠
딥페이크는 어떤 기술인가?
영상 속 A의 얼굴을 B의 얼굴인 것처럼 보이게 하려면 어떻게 해야 할까? A의 얼굴을 B의 얼굴로 바꾸고, B가 A의 음성이나 행위에 맞추어 얼굴을 움직이거나 A와 유사한 표정을 짓도록 해야 할 것이다. 딥페이크를 제대로 이해하기 위해서는 얼굴의 변환 과정을 알아야 한다. 딥페이크로 얼굴을 바꾸기 위해서는 수백 또는 수천 개의 이미지를 인공신경망(ANN·Artificial Neural Network)[1] 에 투입한 후 특징을 식별하고 재구성하도록 훈련하는 작업이 필요하다. 이 과정은 크게 ‘추출(extraction)-학습(learning/training)-병합(creating/merging)’의 세 단계로 구분된다. 딥페이크 기술이 나날이 발전하고 있어 세부적인 원리들은 차이가 있을 수 있으나, 기본적으로 이 세 단계의 과정이 필요하다는 점은 공통적이다.
‘추출’은 A와 B의 얼굴을 바꾸기 전에 컴퓨터가 A와 B의 얼굴 특징이 무엇인지를 먼저 배우는 단계다. 딥페이크 애플리케이션에 A와 B의 사진을 입력하면 기계가 알아서 사진 속 얼굴 부분을 감지(detecting)해 그 부분만 잘라낸 후 잘라낸 부분의 눈, 코, 입의 위치가 서로 맞도록 정렬한다. 사진에서 얼굴의 특징을 인식해 정렬하는 기능은 구글의 ‘텐서플로우(TensorFlow)’나 ‘OpenCV’와 같은 공개 라이브러리와 API, 소프트웨어에 매우 잘 구현돼 있어 기술적으로 어렵지 않고, 결과물의 정확도도 높은 편이다. 다만 대상의 특징을 학습할 수 있는 이미지가 많을수록 추출이 잘 이루어지기 때문에 양질의 데이터를 많이 확보하는 것이 중요하다. 딥페이크가 주로 동영상에서 추출한 이미지를 대상으로 하는 것은 이 때문이다. 동영상은 1초가 수십 개 이미지 프레임의 집합이기 때문에 수백, 수천 장의 얼굴 이미지를 손쉽게 뽑아낼 수 있다. 유명인들이 딥페이크 초창기의 주요 시험 대상이 되었던 것도 특징을 추출하기 위한 데이터의 확보와 관련된다. 유명인들은 기자나 팬들에게 수없이 사진을 찍히고, 웹에 공개되기 때문에 몇 번의 검색만으로도 손쉽게 이미지를 구할 수 있다.
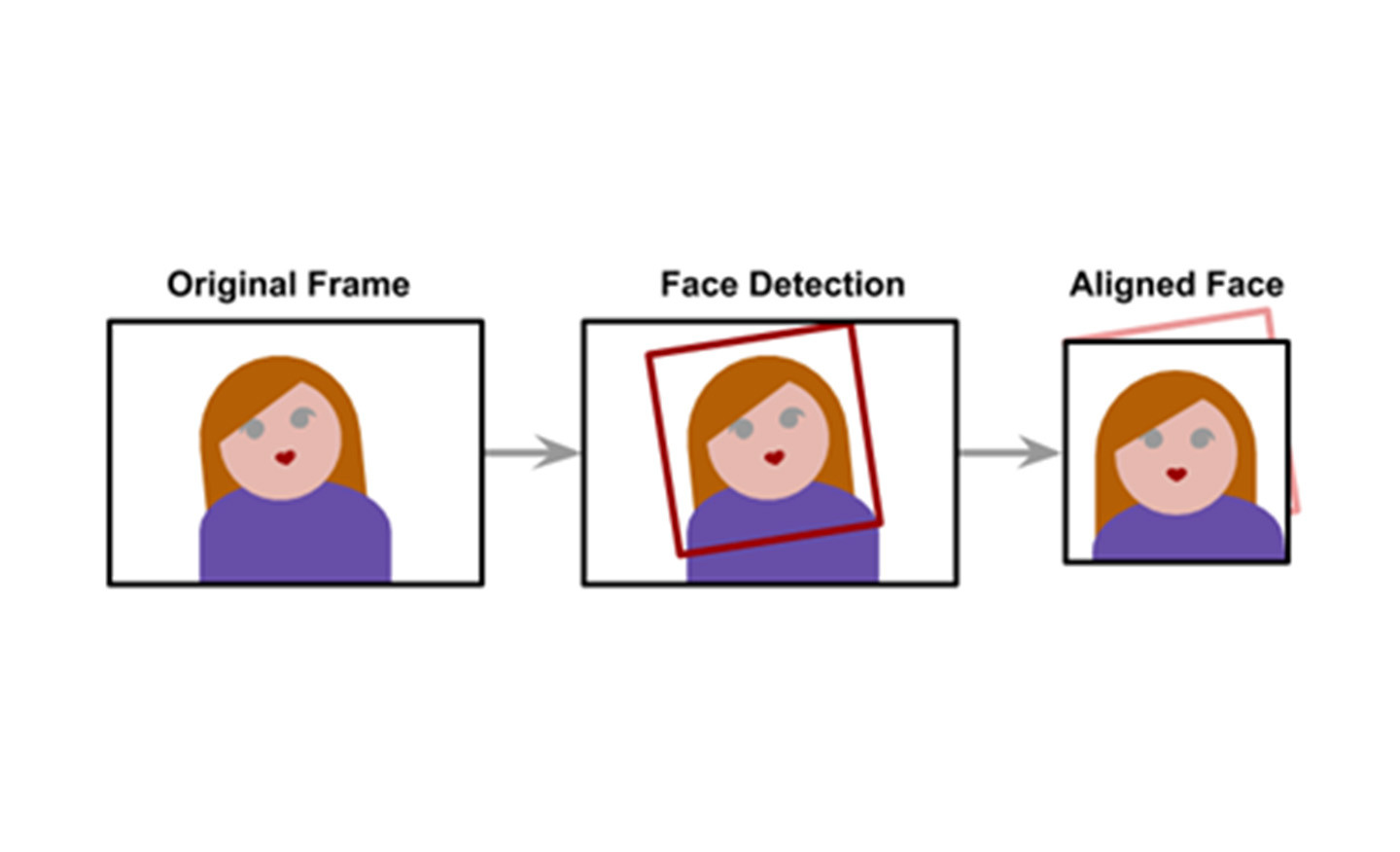
딥페이크의 이미지 추출 과정 ⓒalan zucconi 홈페이지
두 번째 단계는 딥페이크의 핵심인 ‘학습’ 단계다. 학습을 통해 컴퓨터는 추출한 얼굴의 특징을 반영해 원본 영상의 얼굴을 새롭게 구성해 낸다. A 얼굴의 특징을 반영해 B의 얼굴 이미지를 만들어 내고, 반대로 B 얼굴의 특징을 반영해 A의 얼굴 이미지를 만드는 것이다.
학습은 ‘오토인코더(autoencoder)’라고 하는 일종의 ANN에 의존한다. 오토인코더는 인코더와 디코더로 구성된다. 인코더는 이미지에서 중요한 정보만을 추출하는 것이 주목적이다. 고차원의 입력 데이터를 저차원의 표현 벡터로 압축하는 것인데, 이를 전문 용어로 표현하면 “더 낮은 차원의 ‘잠재 공간(latent space)’으로 축소한다”고 말할 수 있다. 디코더는 이렇게 잠재된 표현으로부터 이미지를 재구성해 내는 역할을 한다. 영상에서 A와 B의 얼굴을 바꾸려는 경우, 딥페이크는 같은 구조의 인코더와 디코더를 가진 두 개의 ANN을 사용해 A의 사진에서 A 얼굴의 특징을 학습하는 과정, B의 사진에서 B 얼굴의 특징을 학습하는 과정을 각각 진행한다. 그 결과 두 ANN의 잠재 공간에는 A와 B의 얼굴 특징이 각각 별도로 저장된다. 같은 인코더를 사용했기 때문에 저장된 특징은 동일하다. 가령, A 얼굴에서 눈, 코, 입의 윤곽을 학습했다면 B의 얼굴에서도 눈, 코, 입의 윤곽을 학습하지 귀의 모양을 학습하지는 않는다. 이처럼 동일한 특징을 기준으로 두 ANN의 디코더를 바꿔주면 A의 디코더는 B의 얼굴에서 학습한 특징을 바탕으로 A의 얼굴을 재구성하고, B의 디코더는 A의 특징을 반영해 B의 얼굴을 재구성한다. 이렇게 A와 B의 얼굴이 서로 바뀌게 된다.
학습은 ‘오토인코더(autoencoder)’라고 하는 일종의 ANN에 의존한다. 오토인코더는 인코더와 디코더로 구성된다. 인코더는 이미지에서 중요한 정보만을 추출하는 것이 주목적이다. 고차원의 입력 데이터를 저차원의 표현 벡터로 압축하는 것인데, 이를 전문 용어로 표현하면 “더 낮은 차원의 ‘잠재 공간(latent space)’으로 축소한다”고 말할 수 있다. 디코더는 이렇게 잠재된 표현으로부터 이미지를 재구성해 내는 역할을 한다. 영상에서 A와 B의 얼굴을 바꾸려는 경우, 딥페이크는 같은 구조의 인코더와 디코더를 가진 두 개의 ANN을 사용해 A의 사진에서 A 얼굴의 특징을 학습하는 과정, B의 사진에서 B 얼굴의 특징을 학습하는 과정을 각각 진행한다. 그 결과 두 ANN의 잠재 공간에는 A와 B의 얼굴 특징이 각각 별도로 저장된다. 같은 인코더를 사용했기 때문에 저장된 특징은 동일하다. 가령, A 얼굴에서 눈, 코, 입의 윤곽을 학습했다면 B의 얼굴에서도 눈, 코, 입의 윤곽을 학습하지 귀의 모양을 학습하지는 않는다. 이처럼 동일한 특징을 기준으로 두 ANN의 디코더를 바꿔주면 A의 디코더는 B의 얼굴에서 학습한 특징을 바탕으로 A의 얼굴을 재구성하고, B의 디코더는 A의 특징을 반영해 B의 얼굴을 재구성한다. 이렇게 A와 B의 얼굴이 서로 바뀌게 된다.
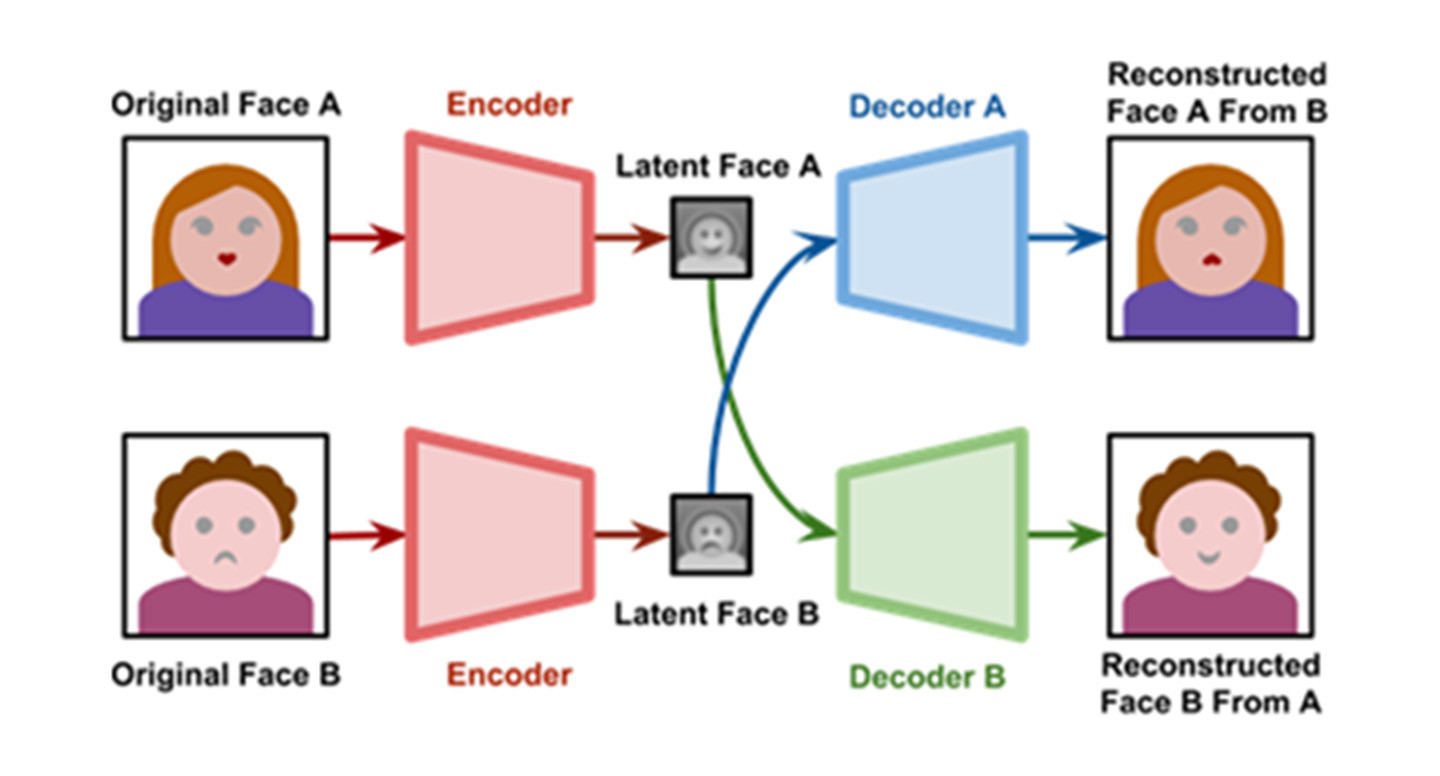
딥페이크의 이미지 학습 과정 ⓒalan zucconi 홈페이지
딥페이크는 ‘생성적 적대 신경망(GAN·Generative Adversarial Network)’을 디코더에 연결하면서 더욱 업그레이드됐다. GAN은 위조지폐범과 경찰이 경쟁하는 과정에서 위조지폐범이 더욱 진짜 같은 위조지폐를 만들게 되는 진화 과정과 닮아있다. 두 개의 신경망(생성 모델과 분류 모델)을 경쟁적(적대적) 관계로 훈련시킴으로써 더욱 진짜 같은 이미지를 만들도록 하는 것이다. 생성 모델의 잠재 공간에 저장된 특징을 기반으로 새롭게 이미지가 만들어지면, 분류 모델의 판별기(discriminator)가 이 이미지의 결함 여부를 포착한다. 분류 모델을 충분히 ‘속일 수 있는’ 이미지를 만들어 내야 하기 때문에 두 모델의 경쟁 속에서 새로운 이미지는 더더욱 원본 이미지와 유사해진다. 이 학습이 잘 이뤄지면 사람의 눈으로는 두 사람의 얼굴 특징이 서로 바뀌어 새롭게 만들어진 이미지라는 것을 쉽게 파악하기 힘들다.
학습이 완료되면 재구성된 얼굴을 원본 이미지에 ‘병합’하는 세 번째 단계가 진행된다. 앞의 두 단계와 달리 이 과정에서는 딥러닝 알고리즘이 적용되지 않는다. 동영상의 프레임마다 인식된 얼굴 부분에 딥페이크가 새롭게 만들어 낸 얼굴을 병합하고 색 조정 정도의 간단한 보정을 거치는 과정이 독립적으로 이뤄진다. 이 과정에서 프레임 간의 시간 연계성(time correlation)은 고려되지 않는다. 즉, 개별 프레임마다 병합 작업을 수행할 뿐, 연속된 프레임 간의 연계가 얼마나 매끄럽게 이뤄지는지는 딥페이크 기술의 고려 대상이 아니다. 이 때문에 최종적으로 완성된 딥페이크 동영상에서 바뀐 얼굴이 조금씩 끊기거나 깜빡거리는 것처럼 보일 수 있다. 이 특징은 특정 동영상의 원본성 여부, 즉 딥페이크 활용 여부를 감지하는 기준이 되기도 한다.
학습이 완료되면 재구성된 얼굴을 원본 이미지에 ‘병합’하는 세 번째 단계가 진행된다. 앞의 두 단계와 달리 이 과정에서는 딥러닝 알고리즘이 적용되지 않는다. 동영상의 프레임마다 인식된 얼굴 부분에 딥페이크가 새롭게 만들어 낸 얼굴을 병합하고 색 조정 정도의 간단한 보정을 거치는 과정이 독립적으로 이뤄진다. 이 과정에서 프레임 간의 시간 연계성(time correlation)은 고려되지 않는다. 즉, 개별 프레임마다 병합 작업을 수행할 뿐, 연속된 프레임 간의 연계가 얼마나 매끄럽게 이뤄지는지는 딥페이크 기술의 고려 대상이 아니다. 이 때문에 최종적으로 완성된 딥페이크 동영상에서 바뀐 얼굴이 조금씩 끊기거나 깜빡거리는 것처럼 보일 수 있다. 이 특징은 특정 동영상의 원본성 여부, 즉 딥페이크 활용 여부를 감지하는 기준이 되기도 한다.
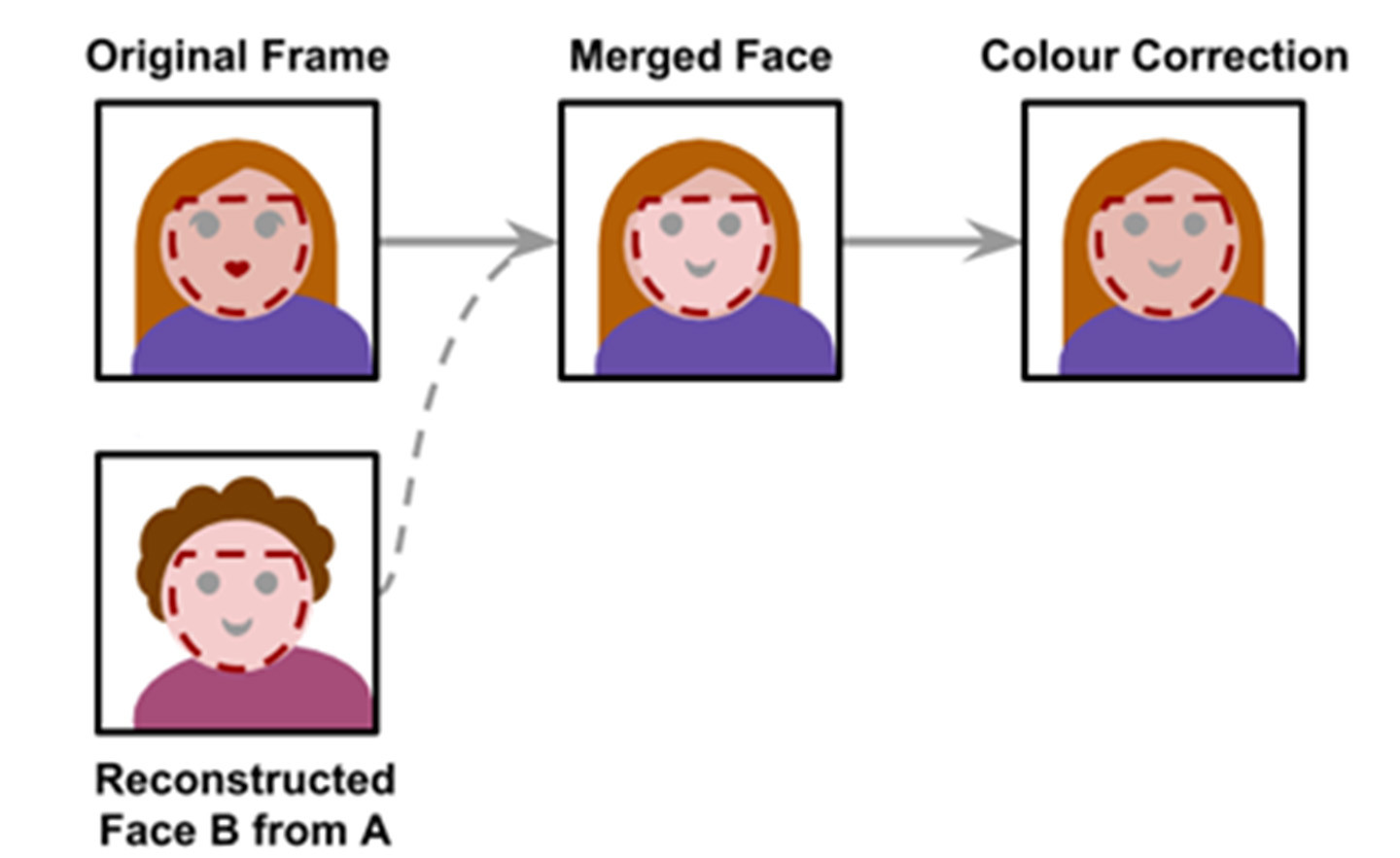
딥페이크의 이미지 병합 과정 ⓒalan zucconi 홈페이지
쉽고, 싸고, 빠른, 딥페이크
딥페이크가 최초의 이미지 합성·조작 기술은 아니다. 어릴 적 사진을 오려 붙여 새로운 이미지를 구성해 내거나 포토샵으로 얼굴을 보정했던 경험이 누구에게나 있을 것이다. 우리는 모두 ‘이미지 조작 기술’을 사용해 왔던 셈이다.
역사적으로 모든 이미지 제작 기술이 발명된 다음에는 그 이미지를 조작하는 기술이 항상 그 뒤를 좇았다. 회화 영역에서는 위작(僞作) 논란이 끊임없이 일었고, 아날로그 필름을 사용하는 사진이나 영화 분야에서는 조작 기술이 특수 효과(special effects·VFX)라는 전문 분야의 발전을 이끌었다. 디지털카메라가 등장하면서 이미지는 그 자체로 이미 보정(retouching)과 조작을 고유한 특성으로 갖게 되는 데 이른다.[2] 포토샵이나 프리미어(Premier)와 같은 이미지, 영상 편집 소프트웨어가 널리 보급됐다는 사실은 디지털 이미지의 조작과 편집이 사회적으로 일상화됐음을 보여준다. 컴퓨터 그래픽이 등장하지 않는 영화를 찾기 어려울 만큼, 디지털 영상 분야에서도 이미지 합성과 조작이 보편화됐다. 그렇다면 딥페이크는 이전의 이미지 조작 기술과 무엇이 다를까?
가장 큰 특징은 이미지의 합성과 조작이 너무나도 쉬워졌다는 것이다. 딥페이크에는 ‘장인의 손길’이 필요 없다. 누구나 사진 한 장만 있다면 얼굴이 뒤바뀐 이미지나 영상을 만들어 낼 수 있다. 딥페이크는 모바일 애플리케이션, 웹사이트 서비스, 오픈 소스 소프트웨어 등 다양한 형태로 서비스되고 있다. 특별한 지식이 없더라도 이용자가 ‘페이스앱 (FaceApp)’ 또는 ‘리페이스(Reface)’와 같은 애플리케이션에 이미지만 선택해서 넣으면 자동으로 얼굴이 뒤바뀐 합성 이미지를 만들어 낼 수 있다. 프로그래밍에 대한 약간의 지식이 있다면, ‘페이스스왑(Faceswap)’이나 ‘딥페이스랩(DeepFaceLab)’과 같은 오픈 소스 소프트웨어를 통해 조금 더 높은 품질의 영상을 만들 수도 있을 것이다.
이미지 합성과 조작에 소요되는 시간과 비용도 현저하게 낮아졌다. 딥러닝 알고리즘을 통해 수천, 수만 장의 이미지가 자동으로 수정되기 때문에, 사람이 프레임별로 이미지를 수정할 때와는 비교할 수 없을 정도로 빠르게 조작된 영상을 만들 수 있다. 기계가 이미지를 ‘학습’하는 데 소요되는 시간은 컴퓨터 성능과 학습할 데이터의 양에 따라 수 시간에서 수십 시간으로 달라지는데, 학습은 단 한 차례만 진행하면 되기 때문에 일단 학습이 이뤄진 후 이미지 합성물을 만드는 과정에는 시간이 오래 걸리지 않는다. 딥페이크 기술을 적용하기 위해 고가의 장비를 갖출 필요도 없다. 딥페이크는 개방형 라이브러리나 API에 의존하고 좋은 결과물을 산출하기 위한 노하우도 대부분 온라인에 공개돼 있어 일정 수준 이상의 그래픽카드만 장착하고 있다면 가정용 PC로도 충분히 딥페이크 영상 합성이 가능하다. 힐러리 클린턴(Hillary Clinton)의 얼굴을 도널드 트럼프(Donald Trump)의 얼굴로 교체한 딥페이크 영상은 700장의 사진을 중저가 그래픽카드(GTX 1060)가 달린 가정용 컴퓨터로 고작 16시간 동안 학습한 결과물이었다.
딥페이크는 쉽고, 싸고, 빠르게 이미지를 만들어 낸다. 그 점에서 딥페이크는 합성 이미지를 위한 상상력, 그리고 이를 구현할 손 기술을 필요로 했던 과거의 이미지 조작과 완전히 다르다. 가령, 인간이 손으로 직접 이미지를 창작하던 회화 시대의 이미지 조작은 새로운 이미지를 다시 만드는 과정과 같았다. 유화를 수정할 때 물감을 덧칠하는 것처럼 이미지를 수정하는 기술은 이미지를 생성하는 기술과 구분되지 않는다. 사실을 기록하는 기법이 곧 거짓을 사실로 조작해 내는 최고의 기법이기도 했던 셈이다. 조작된 이미지가 얼마나 진짜 같은지는 화가의 상상력과 숙련도, 솜씨에 달려 있다. 회화의 시대, 이미지를 생성하거나 조작하는 기술은 오랜 시간의 수련을 통해 습득해야 하는 전문적인 손 기술이었다. 다시 말해, 예술(art)에 가까웠다.
필름에 보존된 빛의 화학적 기록을 통해 이미지를 구현하던 아날로그 사진 시대의 이미지 조작 또한 회화의 시대와 유사하게 사진사의 전문적인 손길에 의존했다. 사진의 기술적 조작은 사진 그 자체만큼이나 오래된 것[3]으로, ‘닷지(dodge)’나, ‘번(burn)’ 등과 같이 촬영 과정에서 발생한 노출 실수를 보완하는 기초적인 조작 기법은 19세기 사진 작업의 핵심적인 부분이자 정규적인 작업이었다.[4] 사진학도의 필독서 중 하나인 마이클 랭포드(Michael Langford)의 책 《암실 테크닉》의 전체 여덟 장 중 세 장이 다양한 조작 기법 설명에만 할애된 것을 봐도 이를 알 수 있다.
아날로그 영상의 이미지 조작은 1902년 조르주 멜리에스(Georges Méliès)의 영화 〈달세계 여행〉 등에서 시도된 것처럼, 주로 극영화에 사용되는 특수 효과 기법을 중심으로 발전했다. 10분 길이의 아날로그 영상을 조작하기 위해서는 최소 1만 장 이상의 스틸 사진을 수정해 내용이 물 흐르듯 이어져야 한다. 사진을 자연스럽게 수정하는 것은 시간과 품이 많이 들고, 사람들이 알아채지 못할 만큼 ‘사실적으로’ 이미지를 만들기 매우 어렵다. 이 때문에 아날로그 영상의 조작은 창작 수준의 자유도를 갖지 못하는 제한된 형태로 이뤄졌다.
디지털 이미지의 시대가 도래한 이후에도 전문가의 영역은 늘 존재했다. 이미지 생산이 폭발적으로 증가한 만큼 이미지 조작 기술 또한 발전했지만, 조작 기술을 제대로 활용하기 위해 디지털 이미지에 대한 지식과 이를 다뤄 본 충분한 경험이 필요하다는 사실은 전과 달라지지 않았다. 포토샵과 같은 이미지 조작 프로그램은 누구나 특별한 도구 없이도 이미지를 합성하고 조작할 수 있도록 만든 계기였지만, 포토샵의 레이어(layer) 구조나 다양한 필터의 효과에 대한 이해, 그리고 이를 잘 적용할 수 있는 손 기술 없이는 최대의 조작 효과를 얻기 어렵다. 디지털 이미지의 시대의 사람들은 이미지 조작을 집에서 컴퓨터만 켜면 할 수 있는 지극히 자연스러운 일로 받아들이게 됐다. 그럼에도 전문적인 지식과 경험이 여전히 필요하다는 점에서 디지털 이미지 조작은 일정 부분 예술의 영역에 걸쳐 있다.
디지털 영상에서 이미지 조작의 예술성은 더욱 극명하게 드러난다. 무한대에 가까운 합성 및 조작 가능성이 제공됐지만, 영상을 수정하는 것은 여전히 어려운 작업이었고 시간과 비용은 도리어 늘어났다. 수정되거나 새로 만들어진 객체를 삽입한 영상은 프레임별 렌더링(rendering) 작업이 필요하기 때문이다. 1993년에 개봉된 영화 〈쥬라기 공원(Jurassic Park)〉의 경우 공룡의 3D 모델을 렌더링하는 작업에 프레임당 두 시간 이상이 소요됐다. 디지털 영상의 합성·조작이 소수의 전문가 집단이나 기업의 업무로 전문화된 것은 이 때문이다.
딥페이크는 전문가가 고가의 장비와 전문 지식을 활용해 수행하던 이미지 합성과 조작을 소프트웨어와 알고리즘이 대신 수행하도록 한다. 딥페이크는 전문가에 국한돼 있던 시각 미디어 조작의 주체를 ‘우리 모두’로 넓히며 비로소 ‘가내화(domestication)’[5]된 셈이다. 디지털 이미지 시대의 포토샵이 그랬던 것처럼 딥페이크는 이제 가정에서 누구나 영상을 조작할 수 있게 해 준다. 그리고 딥페이크는 조작 과정이 자동으로 진행되기 때문에 사람의 손을 거쳐야만 최종 결과물이 생성되는 포토샵과 달리 모두가 영상 조작을 잘할 수 있게 만들어 준다. 시각 미디어 조작 기술이 드디어 예술의 영역에서 벗어나는 것이다.
딥페이크, 심층적 자동화의 기술
이미지와 영상 조작이 인간의 손을 떠났다는 사실은 무엇을 의미하는가? 이전 시대와 차별화되는 딥페이크의 특징을 우리는 ‘심층적 자동화(deep automation)’라 부르고자 한다.
심층적 자동화는 디지털 시대를 주도했던 “선택의 논리(logic of selection)”[6]가 보다 높고 깊은 수준에서 ‘자동화’됨을 의미한다. 디지털 시대에 등장한 각종 이미지 소프트웨어들은 예술가가 지닌 심상과 이를 이미지로 만들어 내는 사회적 과정(the social process)을 분리하며[7] 예술가의 역량 못지않게 조작자의 역량을 중요한 것으로 만들었다. 예술가가 마음에 품은 심상은 예술가의 손 기술과 상관없이 이미지 소프트웨어가 제공하는 스타일과 방법, 절차에 따라 다르게 표현될 수 있는 것이다. 최종적인 결과물은 예술가의 심상보다 이미지 소프트웨어의 기능이나 조작자의 역량에 따라 달라질 수 있다. 이때 조작자의 역량이란 무(無)에서 무언가를 새롭게 창작하는 능력이라기보다는 데이터베이스나 메뉴에 있는 기존 요소들을 선택, 조합하는 역량에 가깝다. 사진을 찍는 능력(생산의 능력)과 사진을 보정하는 능력(조작의 능력)이 동일하지 않으며, 때로는 조작 능력이 더 중요한 위치를 차지할 수도 있는 것이다.
딥페이크는 선택의 논리를 수행하던 조작자의 역량 없이도 이미지를 합성하고 조작할 수 있는 계기를 만들었다. 중요한 것은 데이터의 양과 품질이며, 인간의 역할은 어떤 데이터를 선택할 것인가 하는 가치 판단의 문제로 전환된다. 기존의 이미지 조작 소프트웨어 이용자가 프로그램에 저장된 메뉴를 선택하는 결정자였다면, 딥페이크 이용자는 기계에게 무엇을 학습하고 통제할 것인가를 명령하는, 가치 판단의 집행자가 되는 것이다. 요컨대 딥페이크 이용자가 결정할 것은 누구의 얼굴을 누구의 얼굴로 바꿀지의 문제일 뿐이다.
화가가 손으로 이미지를 생산하던 시대, 이미지 조작은 ‘창작의 논리’를 따랐다. 이미지 생성 기법과 조작 기법이 동일하고, 무엇을 어떻게 조작할 것인지를 화가가 자유롭게 선택할 수 있었기 때문이다. 빛의 화학적 기록이 이미지가 되던 사진의 시대, 이미지 조작은 ‘수정의 논리’를 따랐다. 이미지 조작은 원본 필름이나 인화물을 수정(modification)하는 것으로, 사진가는 제한된 수준에서만 이미지를 조작할 수 있었다. 이미지 처리 소프트웨어가 등장한 디지털 이미지의 시대, 이미지 조작은 ‘선택의 논리’를 따랐다. 합성된 이미지의 품질은 원본 위에 어떤 기능들을 적용하는가 하는 선택과 조합의 역량에 따라 달라졌다.
딥페이크는 창작과 수정, 선택의 과정을 모두 기계의 작업으로 ‘블랙박스화’하며 이미지 합성과 조작을 심층적으로 자동화하고 있다. 인간은 영상을 조작하라는 명령만 내릴 뿐 실제 작업 과정에는 관여하지 않고, 데이터만 충분히 양질이라면 이미지 조작은 인간의 능력에도 구애받지 않는다. 딥페이크의 시대, ‘누가 이미지를 조작했는가’를 넘어 보다 핵심적인 질문들을 던져야 하는 것은 이 때문이다. 딥페이크로 조작된 영상물에 대해서는 창작자가 누구인지보다 ‘창작의 의도’와 만들어진 결과물이 가져올 사회적 파급력을 묻는 것이 훨씬 더 중요하다. 이 책이 딥페이크가 활용된 다양한 사례에 주목하고 그 의미를 헤아려 보려는 것은 이러한 이유에서다.
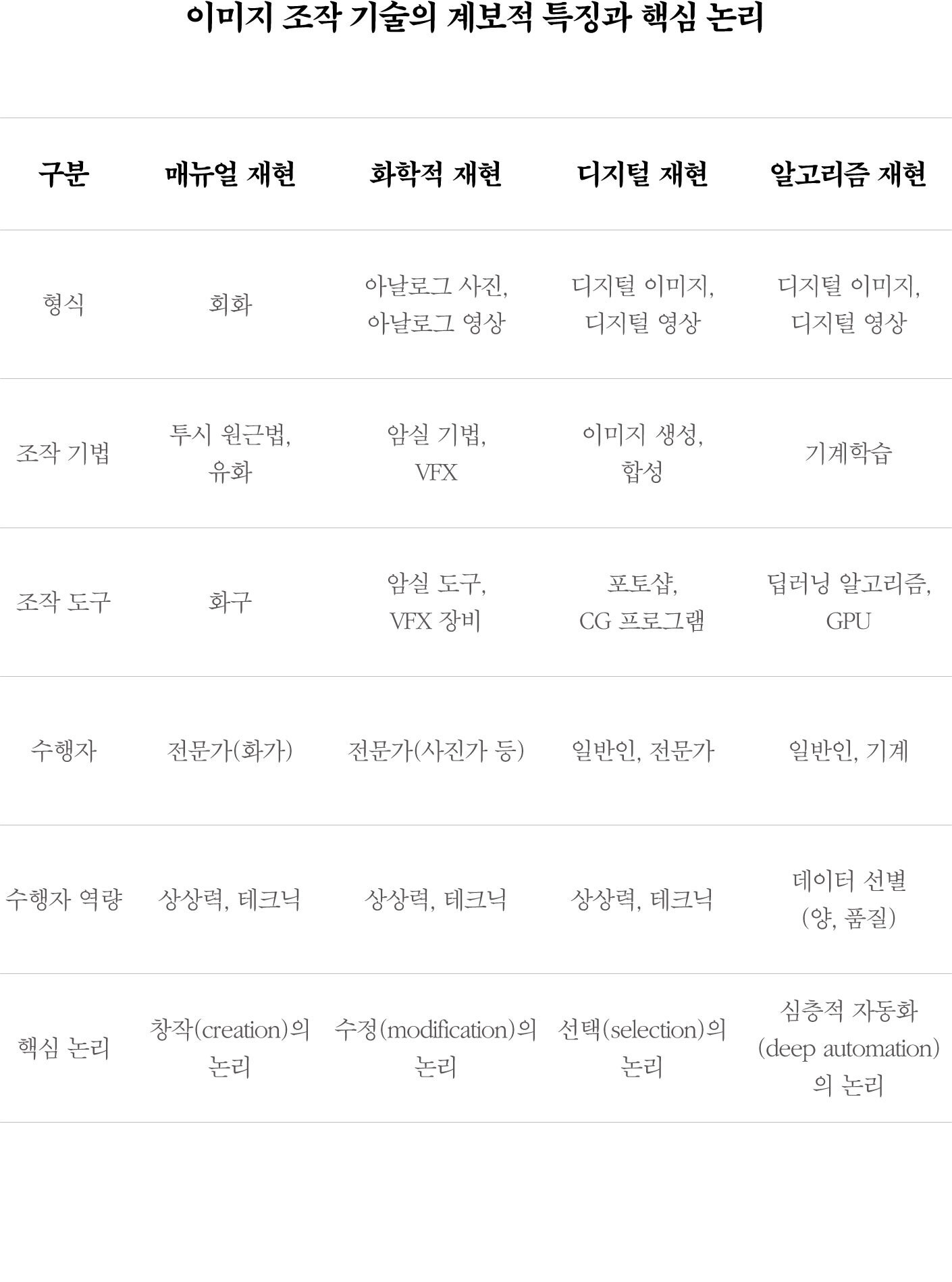
* 출처: 최순욱·오세욱·이소은, 〈딥페이크의 이미지 조작: 심층적 자동화에 따른 사실의 위기와 푼크툼의 생성〉, 《미디어, 젠더 & 문화》, 34(3), 2019., 358쪽.
[1]
두뇌 신경 세포인 뉴런이 연결된 형태를 수학적으로 모델링한 학습 알고리즘이다.
[2]
Lev Manovich, 《The language of new media》, The MIT Press, 2001.
[3]
돈 애즈(이윤희 譯), 《포토몽타주》. 시공사, 2003, 7쪽.
[4]
마이클 랭포드(정성근 譯), 《암실테크닉》, 학문사, 2002, 139쪽.
[5]
가내화는 영국의 문화연구자인 레이몬드 윌리엄스(Raymond Williams) 등이 주창한 개념으로, 발전된 기술이 가정으로 침투해 기존 환경과 통합되고 자연스러운 것으로 인식되는(naturalised) 과정을 말한다.
[6]
Lev Manovich, 《The language of new media》. MIT Press, 2001.
[7]
Luciano Floridi, 〈Digital’s cleaving power and its consequences〉. 《Philosophy & Technology》, 30(2), 2017, pp.123-129.
Close