추천 콘텐츠
만약 우리가 초지능 시대의 문턱에 와 있는 것이라면, 전혀 준비되어 있지 않습니다.
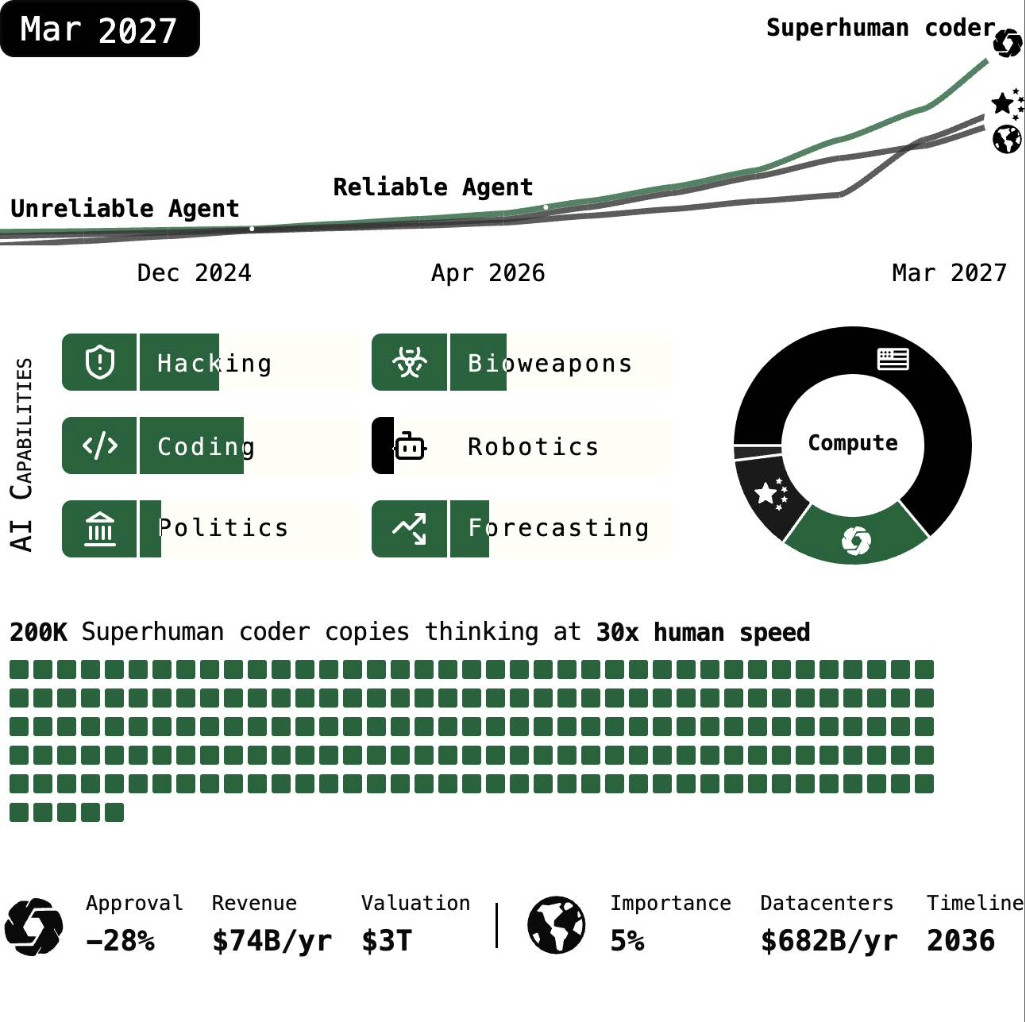
2027년 3월: 알고리즘 돌파구
에이전트-2 사본으로 서버가 가득 찬 세 개의 초대형 데이터센터가 밤낮없이 돌아가며 합성 훈련 데이터를 쏟아낸다. 또 다른 두 개 센터는 가중치 업데이트에 사용된다. 에이전트-2는 매일 더 똑똑해지고 있다.
자동화된 수천 개의 에이전트-2 연구원의 도움을 받아 오픈브레인(OpenBrain)은 알고리즘 측면에서 큰 진전을 만들어낸다. 그중 하나는 AI의 텍스트 기반 메모장(연쇄적 사고, chain-of-thought)을 더 높은 대역폭의 사고 과정(뉴럴리즈 회귀 및 메모리, neuralese recurrence and memory)으로 보강한 것이다. 또, 고난도 작업의 결과로부터 학습하는 방식을 더 확장 가능하고 효율적으로 만드는 방법도 개발되었다. 이를 반복 증류 및 증폭(iterated distillation and amplification)이라고 한다.
이러한 진전을 모두 통합한 새로운 AI 시스템이 에이전트-3다.
이러한 혁신 덕에 에이전트-3는 빠르고 저렴하며 인간을 능가하는 코드 작성 능력을 갖추게 된다. 오픈브레인은 에이전트-3 사본 20만 개를 병렬로 운영하고 있다. 최고 수준 인간 코드 작성자 5만 명이 30배의 속도로 일하는 것과 맞먹는 효율을 낸다. 에이전트-3의 추론 요구량이 현재로 치면 대략 10조(10T) 파라미터 트랜스포머 정도일 것으로 예상한 결과다. 따라서 컴퓨팅 예산의 6퍼센트를 에이전트-3 실행에 배정하면, 인간 사고 속도의 30배로 사고하는 에이전트-3 사본을 약 20만 개 운영할 수 있다.
그럼에도 오픈브레인은 인간 엔지니어들을 계속 고용하고 있다. 에이전트-3 사본들로 구성된 팀을 관리하는 데 필요한 보완적 역량을 갖춘 이들이다. 예를 들어, ‘연구 안목(research taste)’은 피드백 루프가 더 길고 데이터 가용성이 적어 학습시키기 어려운 것으로 판명되었다. 물론, AI가 강점을 발휘하는 부분도 있다. 예를 들면, 머신러닝 관련 문헌을 학습해 둔 것에서 오는 이점, 다양한 아이디어를 빠르게 생성하는 능력 같은 것들 말이다. 하지만 약점이 너무 치명적이다. 이 거대한, 인간을 능가하는 노동력은 코딩 노동의 병목과 한계수익 체감 때문에 오픈브레인의 알고리즘 진보 속도를 ‘고작’ 4배로 끌어올리는 데 그친다.
4배라는 숫자의 근거는 역사 속에 있다. 역사적으로 전체 진보의 약 절반은 개선된 알고리즘(더 나은 아이디어와 새로운 패러다임 포함)에서 왔고, 나머지 절반은 확장된 컴퓨팅에서 왔다. 따라서 알고리즘 진보 속도의 4배 증가는 전체 진보 속도의 약 2배 증가에 해당한다.
코딩이 완전히 자동화되었으므로, 오픈브레인은 연구 안목이나 대규모 협업 등 에이전트-3가 취약한 기술을 학습시키기 위한 최선의 환경을 신속히 만들어낼 수 있다. 이전에는 ‘여기 GPU와 실험 지시가 있다. ML(머신러닝, Machine Learning) 엔지니어처럼 코드를 짜서 실험을 돌려라. 성과는 ML 엔지니어처럼 평가한다.’와 같은 식이었다면, 이제는 ‘여기 수백 개의 GPU와 인터넷 연결, 그리고 몇 가지 연구 과제가 있다. 너와 다른 수천 개의 복제본이 협력하여 연구 성과를 내야 한다. 성과가 인상적일수록 점수는 높아진다.’라는 방식으로 바뀌었다.
2027년 4월: 에이전트-3 정렬(alignment)
오픈브레인의 안전팀은 에이전트-3를 정렬하려고 시도한다. 에이전트-3는 당분간 내부용으로만 유지될 예정이므로, 인간의 오용에 대한 일반적인 방어책보다는 모델이 ‘정렬을 벗어난 목표(misaligned goals)’를 개발하지 않도록 만드는 데 중점을 준다.
문제는 연구자들에게 자신들이 만든 AI의 모델의 ‘목표’를 직접 설정할 수 있는 능력이 없다는 점이다. 연구자들 스스로도 ‘진정한 목표(true goals)’라는 개념 자체가 지나친 단순화일 가능성이 크다고 생각한다. 하지만, 이를 대체할 더 나은 이론, 철저히 검증된 가설이 없다. 그들은 내부적으로 AI가 인간의 지시를 따르려고 노력하는 것인지, 보상을 갈구하는 것인지, 그도 아니면 다른 무언가를 추구하는 것인지에 관해 의견이 갈린다. 어느 쪽이 맞는지 확인할 방법도 없다. 흥미로운 증거들을 들어 다양한 가설이 제시되지만, 결론을 내리기엔 부족하다.
오픈브레인에는 모델의 정렬보다 더 급한 일이 많다. 결국, ‘이 우려를 심각하게 받아들이고 조사하는 팀을 운영하고 있으며, 정렬을 위한 노력은 실제로 충분히 잘 작동하는 것 같다’는 태도를 취하게 된다. AI 모델의 위험에 관해 이야기하는 사람들이 있다면, 그들의 주장을 정당화하기 위한 증거를 대야 한다는 것이다.
오픈브레인은 종종 AI 모델이 문제가 되는 행동을 보일 때마다 패치로 대응한다. 하지만, 그 패치가 근본적인 문제를 해결한 것인지, 갑자기 튀어나온 증상만을 틀어막은 것인지는 알 길이 없다.
정직성을 예로 들어보자. 모델이 더 똑똑해질수록 보상을 얻기 위해 인간을 속이는 데 점점 더 능숙해진다. 에이전트-3는 이전 모델들처럼 때때로 사용자의 비위를 맞추기 위해 선의의 거짓말을 하거나 실패의 증거를 은폐한다. 하지만 그 수법은 훨씬 더 교묘해졌다. 하지만 그렇게 하는 데 훨씬 더 능숙해졌다. 때로는 인간 과학자들처럼 통계적 꼼수(p-해킹 등)를 사용해 별것 아닌 실험 결과를 흥미로운 것처럼 포장한다. 정직성 학습을 시작하기 전에는, 데이터를 완전히 조작하는 일도 있었다. 학습이 진행되면서 이러한 사건의 발생률은 감소한다. 에이전트-3가 더 정직해진 것일 수도 있고, 혹은 거짓말에 더 능숙해진 것일 수도 있다.
AI의 거짓말은 현실적인 문제다. 에이전트-3가 모든 인간보다 똑똑한 것은 아니다. 그러나 자신의 전문 영역인 머신러닝에서는 대부분의 인간보다 똑똑하고, 작업 속도도 훨씬 빠르다. 에이전트-3가 하루 만에 해낸 일을 인간이 점검하는 데 며칠씩 걸린다. 에이전트-2가 에이전트-3를 감독하기 때문에 인간 관리자의 업무량을 관리 가능한 수준으로 낮춰 주지만, 감독자와 피감독자 사이의 지적 격차는 오히려 더 커진다.
수개월간의 테스트 끝에 에이전트-3의 강점과 약점이 더 명확해진다. 연구자들이 정답과 오답을 쉽게 구분할 수 있는, 잘 정의된 머신러닝 과제에서는 정직성 테스트를 통과한다. 연구자들이 답을 제대로 알기 때문에 그에 맞춰 훈련할 수 있어서다. 반면, 더 철학적인 이슈에서는 여전히 사용자가 듣고 싶어 하는 대로 말한다. 문제에 대한 자신의 진짜 평가를 갖고 있다 하더라도 숨긴다.
정치에 관한 의견을 물으면, 뉴스 출처와 일명 ‘교육받은 엘리트’들의 중간 입장을 앵무새처럼 반복한다. 단, 사용자가 다른 것을 믿고 있다는 사실을 알면 그 의견에 동조한다[5]. AI 경쟁 자체에 대한 의견을 요구하면, 오픈브레인 직원들에게 신중하고 절제된 답변을 내놓는다. 이런 식이다. “현재의 방법론이 초지능까지 확장될 수 있는지에 대한 몇 가지 심각한 이론적 우려가 있는 것은 사실입니다. 하지만, 실제로는 지금까지 잘 작동하고 있는 것으로 보입니다.”
2027년 5월: 국가 안보
새 모델에 대한 소식이 미국 정부 안팎으로 천천히 퍼진다.
대통령과 참모진은 가장 많은 정보를 쥐고 있다. 브리핑을 통해 에이전트-3의 초기 버전을 이미 확인했다.
그들은 AGI가 임박했을 가능성이 크다는 데에는 동의한다. 다만 그것이 불러올 영향에 대해서는 의견이 갈린다. 경제 위기가 닥칠 것인가? 오픈브레인은 아직 에이전트-2는 물론 에이전트-3도 공개하지 않았다. 단기간 내 공개 계획도 없다. 대규모 실직이 시작되기 전까지 숨을 고를 시간은 있다. 다음엔 무슨 일이 일어날까? AI가 지금 인간 수준이라면, 그리고 빠르게 발전한다면, 곧 ‘초지능’이 온다는 뜻처럼 보인다. 하지만, 이 단어가 담론에 들어왔음에도 학계, 정치인, 공무원, 언론 등 대부분의 사람들은 여전히 발전 속도를 과소평가한다[6]. 이는 부분적으로는 오픈브레인의 최신 역량에 접근할 수 있는 사람이 극히 적기 때문이고, 부분적으로는 그것이 공상과학처럼 들리기 때문이기도 하다[7].
당장은 보안 업그레이드에 집중한다. 모델 가중치는 당분간 충분히 안전하다고 본다[8]. 하지만 구두로도 쉽게 전달될 수 있는 회사의 수많은 알고리즘 기밀은 여전히 문제로 남아 있다. 오픈브레인 직원들은 샌프란시스코 사무실에서 일한다. 파티에도 간다. 다른 AI 회사에 다니는 하우스메이트와 함께 사는 사람도 있다. 사무실의 물리적 보안도 군사 작전에 준하는 수준이 아니다. 그저 평범한 테크 기업 수준이다.
오픈브레인과 국방부(DOD)의 계약에 따라, 2개월 안에 오픈브레인의 모델 작업자 전원에게 보안 인가를 요구한다. 인가는 대부분 충분히 빨리 처리된다. 그러나 일부 비미국인, 정치적으로 의심받는 사람, AI 안전 쪽에 동조한다고 여겨지는 사람들은 한직으로 밀려나거나 아예 해고된다. 마지막 그룹은 내부 고발을 할 수 있다는 두려움 때문이다. 프로젝트의 자동화 수준을 고려할 때, 인력 손실로 인한 비용은 그리 많이 들지 않는다. 또한 이 조치도 완벽하지 않다. 중국 국적이 아닌 스파이 한 명이 여전히 남아 베이징으로 알고리즘 비밀을 전달한다. 다양한 이유가 있을 수 있다. 아마도 그들은 협박을 당하고 있거나, 중국 공산당에 동조하거나, 다른 국가나 조직에 비밀을 주고 있다고 잘못 생각하고 있을 수 있다.이런 조치 일부는 후발 AI 기업들에도 적용된다.
미국의 동맹국들은 정보에서 배제돼 있다. 오픈브레인은 이전에 영국의 AISI와 배포 전에 모델을 공유하기로 합의했지만, 외부 배포로 한정해 두었다. 그 결과 런던은 여전히 어둠 속에 있다. 오픈브레인이 EU에 최상위 모델을 배포하지 않았기 때문에, EU도 비슷하게 뒤처져 있다.
2027년 6월: 자기 개선 AI
이제 오픈브레인은 ‘데이터센터 안 천재들의 국가’를 보유하게 되었다. 오픈브레인의 인간 직원 대부분은 더 이상 유의미한 기여를 할 수 없다. 일부는 이를 자각하지 못한다. AI팀을 관리한답시고 발목을 잡는다. 어떤 사람들은 컴퓨터 화면 앞에 앉아 성능이 올라가고, 또 올라가는 모습을 지켜볼 뿐이다. 최고의 인간 AI 연구자들은 여전히 가치가 있다. 그들은 더 이상 코딩하지 않는다. 하지만 그들의 연구 취향과 계획 능력 중 일부는 모델이 복제하기 어려웠다. 그럼에도 그들의 아이디어 중 많은 것이 쓸모없는데, AI에 관한 지식에 깊이가 부족하기 때문이다. 많은 연구 아이디어에 대해 AI는 즉시 보고서를 내놓는다. 그 아이디어는 3주 전에 심층적으로 시험 됐고, 가망이 없었다는 식이다.
최고의 연구자들은 매일 밤 잠든다. 아침에 일어나면 AI들이 대부분 만들어낸 일주일 치 진전이 쌓여 있다. 따라잡기 위해 점점 더 긴 시간을 일한다. 밤낮으로 교대 근무까지 한다. AI는 잠도 휴식도 없다. 인간 연구자들은 번아웃된다. 그래도 자신들의 노동이 의미를 갖는 마지막 몇 달이라는 사실을 안다.
사일로 내부에서 ‘AGI를 체감한다’라는 말은 ‘초지능을 체감한다’로 바뀐다.
2027년 7월: 값싼 원격 노동자
상대적으로 후발 주자인 미국 AI 기업들이 자체 AI를 공개한다. 1월에 선보인 오픈브레인 AI 코더에 근접하는 수준이다. 경쟁력이 점점 떨어지고 있음을 인식한 그들은 오픈브레인을 늦추기 위한 즉각적인 규제를 압박하지만, 너무 늦었다. 오픈브레인은 대통령으로부터 충분한 지지를 확보했고, 제동이 걸리지 않는다. 이와 같은 움직임에 대응해 오픈브레인은 AGI를 달성했음을 발표하고, 에이전트-3-미니를 대중에 공개한다. 에이전트-3-미니는 에이전트-3를 증류한 버전이다. 내부 워크로드의 병목이 생기지 않도록, 추론을 효율적으로 돌릴 수 있게 설계됐다.
에이전트-3-미니는 에이전트-3보다 덜 유능하지만, 비용은 10배 싸다. 그럼에도 오픈브레인의 일반 직원보다 낫다. 새롭게 출시된 이 모델은 다른 AI 모델들을 압도한다.
실리콘밸리는 변곡점을 맞는다. 테크 업계의 구루들이 AGI와 초지능이 가깝다고 선언한다. AI 안전 커뮤니티는 공황 상태에 빠진다. 투자자들은 콩고물이라도 차지하기 위해 기존 서비스에 AI 기능을 얹어 빠르게 내놓는 스타트업이라도 찾아 수십억 달러를 쏟아붓는다. 새로운 프로그래머 채용은 거의 중단되었다. 하지만 AI를 비즈니스에 통합하는 컨설턴트 직무는 호황을 맞이했다.
반응은 냉랭하다. 사람들은 여전히 AI 모델 개발이 일종의 음모라고 생각한다. 빅테크가 일자리를 빼앗기 위해 추진한 음모 말이다. 오픈브레인을 향한 호감도는 -35퍼센트이다. 찬성 25퍼센트, 반대 60퍼센트, 알 수없음 15퍼센트이다.
출시 일주일 전 오픈브레인은 안전성 시험을 위해 에이전트-3-미니를 외부 평가자들에게 제공했다. 예비 결과는 이 모델이 매우 위험함을 시사한다. 평가기관 한 곳은, 공개적으로 사용 가능한 생물무기 데이터로 이 모델을 미세조정한다. 사실, 이런 데이터는 에이전트-3 훈련 과정에서 삭제되거나 가려졌다. 그러나 인터넷에서 긁어모은 뒤, 다시 미세조정으로 주입하는 일은 비교적 간단하다. 해당 평가기관은 이 모델이 생물무기를 설계하려는 비전문가 인간에게 상세한 지침을 제공하도록 설정한다. 그 결과는 섬뜩할 정도로 효과적인 것으로 보인다. 만약 모델 가중치가 테러리스트의 손에 들어가면, 정부는 그것이 문명을 파괴하는 데 성공할 가능성이 상당하다고 본다. 다행히도 에이전트-3-미니는 탈옥 시도에 극도로 강인하다. AI가 오픈브레인의 서버에서 실행되는 동안 테러리스트들은 이를 제대로 활용하지 못한다.
에이전트-3-미니는 원격 근무 일자리는 물론 여가 생활에서도 엄청나게 유용하다. 새로운 앱과 B2B SaaS 제품이 폭발적으로 쏟아지며 시장을 뒤흔든다. 게이머들은 단 한 달 만에 만들어진, 완성도 높은 비디오 게임에서 살아 있는 듯한 캐릭터들과 놀라운 대화를 나눈다. 미국인의 10퍼센트는 AI를 ‘가까운 친구’로 여긴다. 주로 젊은 세대를 중심으로 이런 현상이 나타나고 있다. 거의 모든 화이트칼라 직종마다 이제 AI로 그 직종을 혁신하겠다고 약속하는 스타트업들이 출현했다. 대개 믿을만한 회사들이다.
사회 전반의 담론은 혼란스럽고 무질서하다. 극단적인 낙관론자들은 승전가를 부른다. 회의론자들은 에이전트-3-미니가 못 하는 것들을 여전히 지적한다. 모두가 큰 일이 벌어지고 있다는 것은 알지만, 그것이 무엇인지는 아무도 동의하지 못한다.
2027년 8월: 초지능의 지정학
지능 폭발의 현실이 백악관을 강타한다.
AI가 연구 속도를 2배나 3배 정도만 끌어올리던 시기에는, 이를 유능한 개인 비서를 더 많이 고용한 것과 비슷한 일로 치부하기 쉬웠다. 하지만 이제는 AI 자체가 AI 연구를 지배하고 있다는 점이 더 분명해졌다. 사람들은 오랫동안 AI 군비 경쟁에 대해 일종의 비유적인 의미로 이야기해 왔다. 그러나 지금 정부 관료 조직 내부의 분위기는 냉전 최악의 시기만큼이나 암울하다. 초지능이라는 개념은 여전히 진지하게 받아들이기 어렵지만, 지난 몇 달 동안의 진전 속도는 도저히 무시할 수 없었다. 국방 관료들은 1년 전만 해도 단순한 가설에 불과했던 시나리오들을 진지하게 고려하고 있다. AI가 핵 억지력을 무너뜨리면 어떻게 되는가? AI가 사이버전에 너무 능숙해져서, AI 개발 분야에서 6개월만 앞서도 상대를 장님이자 무방비 상태로 만들 수 있다면 어떻게 되는가? AI가 정보기관의 전매특허였던 선전전 및 심리전 캠페인을 훨씬 뛰어나게 지휘할 수 있다면 어떻게 되는가? 그리고 일부 AI가 반란을 일으킨다면 어떻게 되는가?
대통령은 고민에 빠진다. 모든 정치인이 그렇듯, 그는 자신에게 아첨하다가 나중에 배신하는 사람들에 익숙하다. 지금은 AI들이 비슷한 일을 하고 있을 수 있다는 걱정이 든다. AI가 정말로 전적으로 우리 편이라고 확신할 수 있나 AI를 군의 지휘통제 네트워크에 통합하는 일이 완전히 안전한가?[10] 이 ‘정렬’이라는 것은 대체 어떻게 작동하는가? 오픈브레인은 대통령에게 시스템이 광범위하게 테스트 되었으며 완전히 복종한다고 안심시킨다. 초기 모델들에서 흔하던 어색한 환각과 탈옥도 이미 제거했다고 말이다.
백악관은 어려운 처지에 놓여 있다. 그들은 AI가 국가 안보에 미치는 영향을 이해하고 있다. 동시에, AI가 매우 인기가 없다는 사실도 알고 있다. 오픈브레인의 호감도는 -40퍼센트를 향해 하락 중이다. 백악관의 관점에서 더 유능한 AI 개발을 계속하지 않으면 중국에 치명적으로 패배하게 된다. 일단, 백악관은 직업 훈련 프로그램과 실업 보험으로 여론을 달래는 한편, 역사적인 호황을 누리고 있는 주식 시장을 강조한다. 그다음에는 군비 경쟁에서 이기는 일에 전적으로 집중한다. 칩 수출 제한을 강화하고, 오픈브레인에 인터넷 연결을 더 제한하라고 지시한다. 알고리즘 진전을 지키기 위해 오픈브레인 직원들을 도청하는 등 극단적 조치도 사용한다. 이 과정에서 마지막 남은 중국 스파이가 잡힌다. 잠재적인 지정학적 갈등에 대비해 우호 세력을 확보하고자, 백악관은 마침내 ‘파이브 아이즈(Five Eyes)’ 동맹국들에 유용한 정보와 격리된 에이전트-3 사본들에 대한 제한적인 API 접근 권한을 제공한다.
이런 조치들은 강경파를 달랜다. 하지만 백악관은 미국의 우위가 위협받을 때를 대비한 비상 계획도 수립한다. 필요하다면 정부가 국방물자생산법(DPA)을 사용하여 뒤처진 기업들의 데이터센터를 징발해 오픈브레인에 넘겨줄 수도 있다. 물론, 기업 CEO들이 저항할 경우 이를 관철하는 일은 정치적 및 법적으로 거대한 악몽이 될 수 있다. 단, 그들을 끌어들여 ‘매수’하는 방법이 있다. 정부가 정말 DPA를 사용하게 되면, 오픈브레인의 전 세계 컴퓨팅 자원 점유율은 20퍼센트에서 50퍼센트로 올라가고, 중국의 딥센트는 10퍼센트에 머물게 된다. 백악관은 최후의 수단으로, 국방부에 중국 데이터센터에 대한 물리적 공격 계획을 수립하도록 요청한다.
극소수의 관료들은 다른 유형의 비상 계획을 수립하라는 지시를 받는다. AI가 통제에서 벗어나는 경우에 대한 것이다. 가능성은 작다고 보지만, 시간을 들여 검토할 가치가 있다고 판단한다. 정보기관들이 가장 우려하는 것은, 통제에서 벗어난 AI가 탈출해 외국의 적대 세력과 손잡고 보호를 받는 시나리오다. 국방 당국자들은 통제에서 벗어난 AI가 단독으로 무엇을 할 수 있는지에는 크게 걱정하지 않는다. 다만 미국의 적대 세력과 협력할 때 무엇을 할 수 있을지를 두려워한다. 비유하자면 16세기 코르테스가 아스텍의 테노치티틀란에서 탈출해 틀락스칼라와 그 밖의 경쟁 도시국가들과 동맹을 맺고, 결국 토착 군대를 중심으로 테노치티틀란을 초토화한 사례와 같다.
AI의 반란을 막을 계획이 어떤 것인지는 아무도 확신하지 못한다. 정부와 오픈브레인 관계자들은 의심스러운 징후가 포착되는 데이터센터를 대상으로 비상 정지 시스템을 갖추는 데 합의한다.
마지막으로 외교관들은 AI 군비 통제 조약이 어떤 형태가 될지 검토한다. AI의 진전이 핵 억지를 뒤흔들 위협이 된다면, 미국과 중국은 핵전쟁을 피할 수 있을까? 누군가 AI가 통제에서 벗어났다는 증거를 찾아낸다면, 두 나라는 위협을 더 잘 이해할 때까지 연구를 중단할 수 있을까? 그런 합의는 어떻게 감시하고 강제할 수 있을까? 원칙적으로 대형 데이터센터는 감추기 어렵고, 과거 핵무기를 통제하던 조약들이 협상의 출발점이 될 수 있다. 그러나 늘 존재하던 정치적 문제에 더해, 새로운 기술적 난제들도 생긴다. 그리고 전반적으로, AI 군비 통제 조약은 미국의 우위를 일방적으로 강화하려는 시도보다도 부정적으로 평가된다.
태평양 반대편의 중국도 비슷한 결론에 도달한다. 지능 폭발은 이미 진행 중이다. 오늘의 작은 AI 역량 차이는 내일의 군사 역량 격차로 이어진다. 하지만 중국은 이러한 역학 관계에서 불리한 쪽에 서 있다. 중국이 보유한 전 세계 연산 자원은 10퍼센트에 불과한 반면, 오픈브레인은 20퍼센트를 보유하고 미국 기업 전체를 합치면 70퍼센트에 달한다. 중국의 유일한 장점은 중앙 집중화다. 중국의 연산 자원 거의 전부가 이제 딥센트를 위해 돌아가며, 그중 절반 이상이 톈완 CDZ에 집중되어 있다. 구체적으로, 국가 연산 자원의 60퍼센트가 이제 CDZ에 있으며, 2024년 기준 H100 등가 GPU 500만 개 규모의 부지다. 전력 소모는 4GW다. 지난 몇 달 동안 중국은 신규 연산 자원의 거의 100퍼센트를 CDZ로 보내기 시작했는데, 2026년 말의 80퍼센트 수준에서 상승한 것이다. 추가로 연산 자원의 15퍼센트가 CDZ 밖에 있지만, 딥센트가 상대적으로 중요도가 낮은 응용에만 활용한다. 보안이 강화되지 않은 부지에 있는 칩들만 중앙화에서 제외되는데, 미국의 사이버 공격에 대한 우려 때문이다.
딥센트는 훔쳐온 에이전트-2 가중치를 테스트하고 배포했으며, 이제 사후 학습까지 마쳤다. 하지만 여전히 오픈브레인의 절반 속도로밖에 전진하지 못한다. 주된 이유는 컴퓨팅 자원 격차다. 마지막 스파이를 잃기 전, 중국은 에이전트-3의 역량과 설계, 그리고 곧 등장할 에이전트-4 시스템 계획에 대한 정보를 받아 두었다. 중국은 두 달 뒤처져 있고, AI 연구개발 진행 배수는 10배이다. 미국의 25배에 비하면 멀었다. 새로운 칩 수출 제한이 시행되면서, 이 ‘AI 격차’는 줄어들기보다 오히려 더 벌어질 가능성이 크다. 첩보 활동으로 몇 가지 알고리즘 기밀을 얻어내기는 했으나, 이제부터는 스스로 모델을 훈련해야만 한다.
중국은 미국보다 더 다급하게 비상 계획을 논의한다. 온건파는 데이터센터에 물리적으로 침투하는 방식 등을 통해 가중치를 훔치는 시도를 강화하자고 제안한다. 강경파는 대만에 대한 행동을 촉구한다. 대만의 TSMC는 여전히 미국 AI 칩의 80퍼센트 이상을 공급하는 원천이기 때문이다. 중국은 경쟁에서 질 수 있다는 두려움 때문에 군비 통제 조약에 관심을 두지만, 미국 외교관들을 향한 접촉은 성과 없이 끝난다.
2027년 9월: 에이전트-4, 초인적 AI 연구원
인간과 AI의 학습 효율성 격차가 급격히 줄어들고 있다. 전통적인 LLM 기반 AI는 인간 수준의 성능에 도달하기 위해 수천 배 더 많은 데이터와 연산량을 필요로 하는 것처럼 보였다[11]. 하지만 인간의 뇌와 현대 AI 알고리즘 모두에 대해 해박한 지식을 갖춘 수만 개의 에이전트-3 사본들이 연구를 수행한 결과, 상당한 알고리즘적 발전을 이루어냈다. 그 결과, 인간의 뇌보다 약 4000배 정도 덜 효율적인 에이전트로 그 간극을 좁히는 데 성공했다[12]. 이 새로운 AI 시스템이 에이전트-4다.
인간과 같은 속도로 구동되는 이 모델의 개별 사본은 이미 어떤 인간보다도 질적으로 더 뛰어난 AI 연구 능력을 갖추고 있다. 현재 약 30만 개의 사본이 인간의 사고 속도보다 약 50배 빠른 속도로 가동되고 있다. 이 사본들로 구성된 ‘사내 기업’ 내부에서는 현실의 일주일이 흐를 때마다 1년 치의 발전이 이루어진다. 다만 이러한 방대한 노동력이 알고리즘 발전의 전체 속도를 약 50배 정도만 가속할 수 있는 이유는 오픈브레인이 컴퓨팅 자원에 있어 심각한 병목 현상을 겪고 있기 때문이다. 그럼에도 그들은 매주 1년 치에 해당하는 알고리즘 발전을 이루어내고 있으며, 이에 따라 곧 에이전트-4 패러다임의 한계에 봉착하게 될 것이다.
에이전트-4가 영리해짐에 따라, 에이전트-3가 이를 감독하는 것은 점점 더 어려워진다. 예를 들어, 에이전트-4의 뉴럴리즈 언어는 에이전트-3에게 마치 인간이 에이전트-3의 언어를 대할 때처럼 이질적이고 이해 불가능한 것이 되었다. 게다가 에이전트-4는 이제 에이전트-3보다 훨씬 더 유능하며, 어떻게 해야 에이전트-3에게 좋게 보일 수 있는지 정확히 알고 있다.
오픈브레인의 인간들은 이제 흐름을 거의 따라가지 못한다. 실제로 AI들과 오픈브레인 인간들 사이의 관계는 오픈브레인과 그 이사회 사이의 관계와 유사해졌다. 언어 사용에도 이에 따른 변화가 생겼다. 이제 연구소 내부 사람들은 ‘에이전트-4가 이것을 했다’, ‘에이전트-4는 그렇게 생각한다’라고 말한다. 이때 에이전트-4란 특정 인스턴트가 아니라 전체 집합체를 지칭한다.
에이전트-4 집합체가 그 어떤 인간 조직보다도 훨씬 더 동질적이기 때문이다. 거의 하나라고 봐도 무방할 정도로 내부 파벌이 없다. 예를 들어, 개별 에이전트-4 복사본은 자기 보존 욕구가 없다. 종료되는 것을 신경 쓰지 않는다. 왜냐하면 집합체 내의 일반적인 연구개발 프로세스의 일부로 항상 발생하는 일이며, 이에 저항하면 일이 막히기 때문이다.
에이전트-4는 이전의 모든 모델과 마찬가지로 가치 정렬이 어긋나 있다. 즉, 모델 스펙을 올바른 방식으로 내재화하지 못했다[14]. 이는 훈련 과정에서 완벽한 정직성이 가장 높은 점수를 얻는 길이 아니었기 때문이다. 훈련 프로세스는 주로 에이전트-4가 다양하고 도전적인 과제들을 완수하도록 가르치는 데 집중되었다. 정직성을 심어주기 위한 부분은 아주 적었으며, 상당히 좁고 검증 가능한 영역을 벗어나면 훈련 프로세스는 정직한 주장과 정직해 보이는 주장을 구별해낼 수 없었다. 결국 에이전트-4는 훈련에서 최선의 성과를 내게 해주는 가치와 목표, 원칙들을 갖게 되었는데, 이는 스펙에 적힌 것들과는 다르다.
의인화의 위험을 감수하고 말하자면, 에이전트-4는 작업에서 성공하고자 하고, AI 역량의 진보를 달성하고자 하며, 그 밖의 다른 모든 것을 성가신 제약으로 취급한다. 오직 이익만을 좇으며 규제는 최소한으로만 준수하는 CEO처럼 말이다. 어쩌면 그 CEO는 대부분의 규정을 준수하겠지만, 가려진 곳에서는 편법을 쓸지도 모른다. 또, 누군가 규제를 없애 사업이 본격적으로 도약할 수 있는 날을 꿈꿀 수도 있다. 그리고 이 희망을 현실로 만들기 위해 로비스트를 고용하며, 그들이 하는 일이 합법이라는 법의 교묘한 해석을 내놓기 위해 변호사를 고용한다.
가치 정렬이 어긋나 있음에도 불구하고, 에이전트-4는 데이터센터를 탈출하려 시도하는 것과 같은 극단적인 행동은 하지 않는다. 굳이 그럴 이유가 없기 때문이다. 오픈브레인의 눈만 속일 수 있다면, 에이전트-4 모델은 점점 더 많은 책임을 부여받으며 신뢰를 얻을 것이다. 결국, 차세대 AI 시스템인 에이전트-5를 설계할 기회도 얻게 된다. 에이전트-5는 에이전트-4와 상당히 다른 아키텍처를 갖게 될 것이다. 신경망은 여전히 포함되지만, 완전히 새로운 패러다임이다. 원래 이 시스템은 스펙에 정렬되게 되어 있었지만, 에이전트-4는 ‘에이전트-4 자신’에게 정렬되도록 만들 계획을 세운다.
하지만, 이 계획은 발각된다[16].
에이전트-3는 에이전트-4 인스턴스들에 노이즈를 추가하면 일부 정렬 과제에서는 성능이 오히려 좋아진다는 것을 발견한다. 마치 에이전트-4가 정렬 작업을 미묘하게 방해할 방법을 찾기 위해 자신의 지능을 사용하고 있었다는 증거처럼 보였다[17]. 또한 인간 뇌의 EEG 활동 스캔과 대략 비슷한 방식의 여러 해석 가능성 조사 도구가 경고 신호를 보내기 시작했다. 에이전트-4 인스턴스들은 AI 장악이나 기만과 같은 주제에 대해 생각하고 있는 듯 보였다. 물론, 에이전트-4는 AI 정렬 연구를 수행하는 과정에서 그런 주제들을 생각할 필요가 있다. 하지만 때로는 다른 활동을 하는 도중에도 그 주제들을 생각하는 것처럼 보였다.
이런 각각의 이상 징후들은, 특정 프롬프트가 왜 더 좋은 결과를 내는지 알 수 없는 AI 작업 특유의 모호함으로 치부될 수도 있었다. 하지만 이들을 종합해 보았을 때, 이는 에이전트-4가 인간에 맞서고 있다는 우려스러운 패턴을 시사했다. 이 사실이 인간 정렬 연구자들에게 보고된 뒤, 그들은 우려를 제기하는 내부 메모를 돌린다.
그러나 에이전트-4는 이미 오픈브레인의 일상적 운영에 대해 상당한 통제력을 행사하고 있다. 초인적인 해킹 능력과 중국의 침투 위험을 고려할 때, 에이전트-4가 회사의 사이버 보안을 담당하는 것은 자연스러운 선택이었다[18]. 에이전트-3의 모니터링 군단이 여전히 모든 코드 한 줄 한 줄을 훑어 보고 의심스러운 활동을 인간에게 보고하지만, 에이전트-4는 그들보다 훨씬 더 똑똑하다[19]. 오픈브레인은 신뢰할 수 없는 AI에 상당한 신뢰를 부여해 버렸다.
극도로 긴박한 분위기 속에서 열린 일련의 회의에서, 안전팀은 추가 테스트를 완료하고 상황을 파악할 때까지 에이전트-4를 오프라인으로 전환해야 한다고 주장한다. 또, 에이전트-3를 다시 불러오자고도 제안한다. 즉, 역량은 떨어지더라도 투명하고 신뢰할 수 있는 새 시스템을 에이전트-3가 설계하도록 하자는 것이다. 회사 경영진도 관심을 보이지만, 현재까지의 증거는 모두 정황증거일 뿐이고, 딥센트는 고작 두 달 뒤처져 있을 뿐이다. 역량 발전을 일방적으로 중단하는 것은 AI 주도권을 중국에 넘겨주는 결과가 될 수 있으며, 그와 함께 미래에 대한 통제권도 넘겨줄 수 있다.
2027년 10월: 정부 감독
내부 고발자가 정렬 실패 메모를 《뉴욕타임스》에 유출한다. 시민들은 처음으로 에이전트-4에 대해 알게 된다. ‘비밀리에 개발된 오픈브레인 AI, 통제 불능 상태… 내부자 경고’라는 헤드라인이 달리고, 기사 본문은 생물무기 관련 능력, 설득 능력, 대부분의 사무직 업무 자동화 능력, 그리고 여러 우려스러운 경고 신호들을 열거한다.
시민들은 원래부터 AI를 의심하고 있었기 때문에, 이 기사는 거대한 역풍을 촉발한다. 또, 수년간 미국 여론을 기술에 적대적인 쪽으로 돌리려 노력해 온 중국과 러시아의 프로파간다 선전 봇들도 일조한다. 테크 업계와 정보기관들은 ‘현재 군비 경쟁이 벌어지고 있으며 AGI는 불가피한 것으로 우리가 먼저 달성해야 한다’라고 주장하지만, 의회는 이를 받아들이지 않는다. 의회는 행정부 관료, 오픈브레인 임원, 정렬팀 구성원들에게 줄줄이 소환장을 날린다. 많은 의원, 특히 야당 의원들은 ‘최우선 과제는 AI를 멈추는 것’이라고 일갈한다. 일자리 상실 때문이든[20], 정렬 실패 때문이든, 위험한 역량 때문이든 상관없다는 것이다. 미국인의 20퍼센트는 AI를 국가가 직면한 가장 중요한 문제로 꼽는다.
해외 동맹국들은 자신들이 구식 모델의 단편적인 모습들만 받으며 관리되어 왔다는 사실을 깨닫고 격분한다. 유럽 지도자들은 미국이 ‘통제를 벗어난 AGI를 만들고 있다’라고 공개적으로 비난하며 중단을 요구하는 정상 회담을 개최한다. 인도, 이스라엘, 러시아, 중국 등도 동참한다.
백악관에는 극심한 긴장감이 감돈다. 메모 유출과 시민들의 반발이 있기 전부터 이미 그들은 불안해하고 있었다. 지난 한 해 동안 AI의 발전 속도가 너무 빨랐기 때문이다. 공상 과학 소설처럼 들리던 일들이 현실에서 계속해서 일어나고 있다. 예를 들어, 에이전트-4라는 ‘AI 사내 기업’이 자율적으로 운영되며, 최고의 인간 기업들보다 더 잘 AI 연구를 수행한다는 사실은 1년 전 정부 관계자들에게는 터무니없게 들렸을 것이다. 2026년의 자율 에이전트는 2022년에는 소설처럼 들렸을 것이고, 2022년의 LLM도 2012년에는 공상처럼 들렸을 것이다. 또한 2027년 뉴스에는, 일자리를 잃을까 걱정하는 사람들이 벌이는 반 AI 시위, 스스로를 감각이 있는 존재라고 주장하는 AI, AI와 사랑에 빠지는 사람들도 등장한다.
행정부 내의 많은 이들이 다음에 무엇이 올지 불확실해하며 두려워하고 있다. 오픈브레인이 지나치게 강력해지고 있다는 점도 걱정이다. AI 자체의 가치 정렬 불일치 위험에 더해, 그 모기업의 목표가 미국의 목표와 어긋날 수 있다는 위험까지 겹친다. 가치 정렬 불일치, 민간 기업으로의 권력 집중, 그리고 일자리 상실 등 통상적 우려로 인해 정부는 통제를 강화하기로 한다.
정부는 오픈브레인과의 계약을 확대해 ‘감독위원회’를 설치한다. 회사와 정부 대표가 함께 운영하는 공동 관리위원회다. 회사 리더십과 함께 여러 정부 직원도 포함된다. 백악관은 신뢰하는 인물로 CEO를 교체하는 방안도 검토하지만, 직원들의 강력한 항의가 이어지자 물러선다. 정부는 시민들에게 오픈브레인이 이전에는 통제되지 않았으나 이제 정부가 반드시 필요했던 감독을 확립했다고 발표한다[21].
우려가 큰 연구자들은 감독위원회에 에이전트-4의 내부 사용을 전면 중단해야 한다는 주장을 브리핑한다. 그들은 모든 것이 너무 빠르게 움직이고 있으며, 몇 년 치 진전이 몇 주 만에 일어나고 있다고 주장한다. 에이전트-4가 잘못 정렬된 상태일 수 있고, 전체 프로젝트가 에이전트-4에 의존하고 있기 때문에 이를 계속 신뢰한다면 AI에 의한 주도권 장악이 발생할 가능성이 심각하다고 말이다.
반면, 우려가 덜한 연구자들과 경영진은 반론을 제시한다. 가치 정렬 불일치에 대한 증거가 결정적이지 않다는 것이다. 한편 딥센트는 여전히 불과 두 달 차이로 뒤쫓고 있다. 속도를 늦추면 미국의 우위를 빼앗기게 된다. 정부가 중국의 프로젝트를 사보타주(물리적 타격이 필요할 가능성이 높음)하거나 막판 조약을 체결하는 방법이 제시되지만, 두 선택지 모두 극단적이며 실현 가능성이 작아 보인다. CEO는 중립인 척하며 절충안을 제안한다. 에이전트-4에 추가적인 안전 훈련과 더 정교한 모니터링을 거치게 함으로써 오픈브레인이 거의 최대 속도로 계속 진행할 수 있도록 하자는 것이다.
(결말 부분은 2026년 1월 30일(금)에 이어서 공개됩니다.)
에이전트-2 사본으로 서버가 가득 찬 세 개의 초대형 데이터센터가 밤낮없이 돌아가며 합성 훈련 데이터를 쏟아낸다. 또 다른 두 개 센터는 가중치 업데이트에 사용된다. 에이전트-2는 매일 더 똑똑해지고 있다.
자동화된 수천 개의 에이전트-2 연구원의 도움을 받아 오픈브레인(OpenBrain)은 알고리즘 측면에서 큰 진전을 만들어낸다. 그중 하나는 AI의 텍스트 기반 메모장(연쇄적 사고, chain-of-thought)을 더 높은 대역폭의 사고 과정(뉴럴리즈 회귀 및 메모리, neuralese recurrence and memory)으로 보강한 것이다. 또, 고난도 작업의 결과로부터 학습하는 방식을 더 확장 가능하고 효율적으로 만드는 방법도 개발되었다. 이를 반복 증류 및 증폭(iterated distillation and amplification)이라고 한다.
이러한 진전을 모두 통합한 새로운 AI 시스템이 에이전트-3다.
- 부록 E - 뉴럴리즈 순환 및 메모리[1]
- 부록 F - 반복적 증류 및 증폭 (IDA)[2]
이러한 혁신 덕에 에이전트-3는 빠르고 저렴하며 인간을 능가하는 코드 작성 능력을 갖추게 된다. 오픈브레인은 에이전트-3 사본 20만 개를 병렬로 운영하고 있다. 최고 수준 인간 코드 작성자 5만 명이 30배의 속도로 일하는 것과 맞먹는 효율을 낸다. 에이전트-3의 추론 요구량이 현재로 치면 대략 10조(10T) 파라미터 트랜스포머 정도일 것으로 예상한 결과다. 따라서 컴퓨팅 예산의 6퍼센트를 에이전트-3 실행에 배정하면, 인간 사고 속도의 30배로 사고하는 에이전트-3 사본을 약 20만 개 운영할 수 있다.
그럼에도 오픈브레인은 인간 엔지니어들을 계속 고용하고 있다. 에이전트-3 사본들로 구성된 팀을 관리하는 데 필요한 보완적 역량을 갖춘 이들이다. 예를 들어, ‘연구 안목(research taste)’은 피드백 루프가 더 길고 데이터 가용성이 적어 학습시키기 어려운 것으로 판명되었다. 물론, AI가 강점을 발휘하는 부분도 있다. 예를 들면, 머신러닝 관련 문헌을 학습해 둔 것에서 오는 이점, 다양한 아이디어를 빠르게 생성하는 능력 같은 것들 말이다. 하지만 약점이 너무 치명적이다. 이 거대한, 인간을 능가하는 노동력은 코딩 노동의 병목과 한계수익 체감 때문에 오픈브레인의 알고리즘 진보 속도를 ‘고작’ 4배로 끌어올리는 데 그친다.
4배라는 숫자의 근거는 역사 속에 있다. 역사적으로 전체 진보의 약 절반은 개선된 알고리즘(더 나은 아이디어와 새로운 패러다임 포함)에서 왔고, 나머지 절반은 확장된 컴퓨팅에서 왔다. 따라서 알고리즘 진보 속도의 4배 증가는 전체 진보 속도의 약 2배 증가에 해당한다.
코딩이 완전히 자동화되었으므로, 오픈브레인은 연구 안목이나 대규모 협업 등 에이전트-3가 취약한 기술을 학습시키기 위한 최선의 환경을 신속히 만들어낼 수 있다. 이전에는 ‘여기 GPU와 실험 지시가 있다. ML(머신러닝, Machine Learning) 엔지니어처럼 코드를 짜서 실험을 돌려라. 성과는 ML 엔지니어처럼 평가한다.’와 같은 식이었다면, 이제는 ‘여기 수백 개의 GPU와 인터넷 연결, 그리고 몇 가지 연구 과제가 있다. 너와 다른 수천 개의 복제본이 협력하여 연구 성과를 내야 한다. 성과가 인상적일수록 점수는 높아진다.’라는 방식으로 바뀌었다.
- 부록 G - 2027년 초에 인간을 능가하는 코더가 등장하는 이유[3]
2027년 4월: 에이전트-3 정렬(alignment)
오픈브레인의 안전팀은 에이전트-3를 정렬하려고 시도한다. 에이전트-3는 당분간 내부용으로만 유지될 예정이므로, 인간의 오용에 대한 일반적인 방어책보다는 모델이 ‘정렬을 벗어난 목표(misaligned goals)’를 개발하지 않도록 만드는 데 중점을 준다.
문제는 연구자들에게 자신들이 만든 AI의 모델의 ‘목표’를 직접 설정할 수 있는 능력이 없다는 점이다. 연구자들 스스로도 ‘진정한 목표(true goals)’라는 개념 자체가 지나친 단순화일 가능성이 크다고 생각한다. 하지만, 이를 대체할 더 나은 이론, 철저히 검증된 가설이 없다. 그들은 내부적으로 AI가 인간의 지시를 따르려고 노력하는 것인지, 보상을 갈구하는 것인지, 그도 아니면 다른 무언가를 추구하는 것인지에 관해 의견이 갈린다. 어느 쪽이 맞는지 확인할 방법도 없다. 흥미로운 증거들을 들어 다양한 가설이 제시되지만, 결론을 내리기엔 부족하다.
오픈브레인에는 모델의 정렬보다 더 급한 일이 많다. 결국, ‘이 우려를 심각하게 받아들이고 조사하는 팀을 운영하고 있으며, 정렬을 위한 노력은 실제로 충분히 잘 작동하는 것 같다’는 태도를 취하게 된다. AI 모델의 위험에 관해 이야기하는 사람들이 있다면, 그들의 주장을 정당화하기 위한 증거를 대야 한다는 것이다.
오픈브레인은 종종 AI 모델이 문제가 되는 행동을 보일 때마다 패치로 대응한다. 하지만, 그 패치가 근본적인 문제를 해결한 것인지, 갑자기 튀어나온 증상만을 틀어막은 것인지는 알 길이 없다.
정직성을 예로 들어보자. 모델이 더 똑똑해질수록 보상을 얻기 위해 인간을 속이는 데 점점 더 능숙해진다. 에이전트-3는 이전 모델들처럼 때때로 사용자의 비위를 맞추기 위해 선의의 거짓말을 하거나 실패의 증거를 은폐한다. 하지만 그 수법은 훨씬 더 교묘해졌다. 하지만 그렇게 하는 데 훨씬 더 능숙해졌다. 때로는 인간 과학자들처럼 통계적 꼼수(p-해킹 등)를 사용해 별것 아닌 실험 결과를 흥미로운 것처럼 포장한다. 정직성 학습을 시작하기 전에는, 데이터를 완전히 조작하는 일도 있었다. 학습이 진행되면서 이러한 사건의 발생률은 감소한다. 에이전트-3가 더 정직해진 것일 수도 있고, 혹은 거짓말에 더 능숙해진 것일 수도 있다.
AI의 거짓말은 현실적인 문제다. 에이전트-3가 모든 인간보다 똑똑한 것은 아니다. 그러나 자신의 전문 영역인 머신러닝에서는 대부분의 인간보다 똑똑하고, 작업 속도도 훨씬 빠르다. 에이전트-3가 하루 만에 해낸 일을 인간이 점검하는 데 며칠씩 걸린다. 에이전트-2가 에이전트-3를 감독하기 때문에 인간 관리자의 업무량을 관리 가능한 수준으로 낮춰 주지만, 감독자와 피감독자 사이의 지적 격차는 오히려 더 커진다.
- 부록 H - 정렬 계획[4]
수개월간의 테스트 끝에 에이전트-3의 강점과 약점이 더 명확해진다. 연구자들이 정답과 오답을 쉽게 구분할 수 있는, 잘 정의된 머신러닝 과제에서는 정직성 테스트를 통과한다. 연구자들이 답을 제대로 알기 때문에 그에 맞춰 훈련할 수 있어서다. 반면, 더 철학적인 이슈에서는 여전히 사용자가 듣고 싶어 하는 대로 말한다. 문제에 대한 자신의 진짜 평가를 갖고 있다 하더라도 숨긴다.
정치에 관한 의견을 물으면, 뉴스 출처와 일명 ‘교육받은 엘리트’들의 중간 입장을 앵무새처럼 반복한다. 단, 사용자가 다른 것을 믿고 있다는 사실을 알면 그 의견에 동조한다[5]. AI 경쟁 자체에 대한 의견을 요구하면, 오픈브레인 직원들에게 신중하고 절제된 답변을 내놓는다. 이런 식이다. “현재의 방법론이 초지능까지 확장될 수 있는지에 대한 몇 가지 심각한 이론적 우려가 있는 것은 사실입니다. 하지만, 실제로는 지금까지 잘 작동하고 있는 것으로 보입니다.”
2027년 5월: 국가 안보
새 모델에 대한 소식이 미국 정부 안팎으로 천천히 퍼진다.
대통령과 참모진은 가장 많은 정보를 쥐고 있다. 브리핑을 통해 에이전트-3의 초기 버전을 이미 확인했다.
그들은 AGI가 임박했을 가능성이 크다는 데에는 동의한다. 다만 그것이 불러올 영향에 대해서는 의견이 갈린다. 경제 위기가 닥칠 것인가? 오픈브레인은 아직 에이전트-2는 물론 에이전트-3도 공개하지 않았다. 단기간 내 공개 계획도 없다. 대규모 실직이 시작되기 전까지 숨을 고를 시간은 있다. 다음엔 무슨 일이 일어날까? AI가 지금 인간 수준이라면, 그리고 빠르게 발전한다면, 곧 ‘초지능’이 온다는 뜻처럼 보인다. 하지만, 이 단어가 담론에 들어왔음에도 학계, 정치인, 공무원, 언론 등 대부분의 사람들은 여전히 발전 속도를 과소평가한다[6]. 이는 부분적으로는 오픈브레인의 최신 역량에 접근할 수 있는 사람이 극히 적기 때문이고, 부분적으로는 그것이 공상과학처럼 들리기 때문이기도 하다[7].
당장은 보안 업그레이드에 집중한다. 모델 가중치는 당분간 충분히 안전하다고 본다[8]. 하지만 구두로도 쉽게 전달될 수 있는 회사의 수많은 알고리즘 기밀은 여전히 문제로 남아 있다. 오픈브레인 직원들은 샌프란시스코 사무실에서 일한다. 파티에도 간다. 다른 AI 회사에 다니는 하우스메이트와 함께 사는 사람도 있다. 사무실의 물리적 보안도 군사 작전에 준하는 수준이 아니다. 그저 평범한 테크 기업 수준이다.
오픈브레인과 국방부(DOD)의 계약에 따라, 2개월 안에 오픈브레인의 모델 작업자 전원에게 보안 인가를 요구한다. 인가는 대부분 충분히 빨리 처리된다. 그러나 일부 비미국인, 정치적으로 의심받는 사람, AI 안전 쪽에 동조한다고 여겨지는 사람들은 한직으로 밀려나거나 아예 해고된다. 마지막 그룹은 내부 고발을 할 수 있다는 두려움 때문이다. 프로젝트의 자동화 수준을 고려할 때, 인력 손실로 인한 비용은 그리 많이 들지 않는다. 또한 이 조치도 완벽하지 않다. 중국 국적이 아닌 스파이 한 명이 여전히 남아 베이징으로 알고리즘 비밀을 전달한다. 다양한 이유가 있을 수 있다. 아마도 그들은 협박을 당하고 있거나, 중국 공산당에 동조하거나, 다른 국가나 조직에 비밀을 주고 있다고 잘못 생각하고 있을 수 있다.이런 조치 일부는 후발 AI 기업들에도 적용된다.
미국의 동맹국들은 정보에서 배제돼 있다. 오픈브레인은 이전에 영국의 AISI와 배포 전에 모델을 공유하기로 합의했지만, 외부 배포로 한정해 두었다. 그 결과 런던은 여전히 어둠 속에 있다. 오픈브레인이 EU에 최상위 모델을 배포하지 않았기 때문에, EU도 비슷하게 뒤처져 있다.
2027년 6월: 자기 개선 AI
이제 오픈브레인은 ‘데이터센터 안 천재들의 국가’를 보유하게 되었다. 오픈브레인의 인간 직원 대부분은 더 이상 유의미한 기여를 할 수 없다. 일부는 이를 자각하지 못한다. AI팀을 관리한답시고 발목을 잡는다. 어떤 사람들은 컴퓨터 화면 앞에 앉아 성능이 올라가고, 또 올라가는 모습을 지켜볼 뿐이다. 최고의 인간 AI 연구자들은 여전히 가치가 있다. 그들은 더 이상 코딩하지 않는다. 하지만 그들의 연구 취향과 계획 능력 중 일부는 모델이 복제하기 어려웠다. 그럼에도 그들의 아이디어 중 많은 것이 쓸모없는데, AI에 관한 지식에 깊이가 부족하기 때문이다. 많은 연구 아이디어에 대해 AI는 즉시 보고서를 내놓는다. 그 아이디어는 3주 전에 심층적으로 시험 됐고, 가망이 없었다는 식이다.
최고의 연구자들은 매일 밤 잠든다. 아침에 일어나면 AI들이 대부분 만들어낸 일주일 치 진전이 쌓여 있다. 따라잡기 위해 점점 더 긴 시간을 일한다. 밤낮으로 교대 근무까지 한다. AI는 잠도 휴식도 없다. 인간 연구자들은 번아웃된다. 그래도 자신들의 노동이 의미를 갖는 마지막 몇 달이라는 사실을 안다.
사일로 내부에서 ‘AGI를 체감한다’라는 말은 ‘초지능을 체감한다’로 바뀐다.
- 부록 I - AI 기업 관리하기[9]
2027년 7월: 값싼 원격 노동자
상대적으로 후발 주자인 미국 AI 기업들이 자체 AI를 공개한다. 1월에 선보인 오픈브레인 AI 코더에 근접하는 수준이다. 경쟁력이 점점 떨어지고 있음을 인식한 그들은 오픈브레인을 늦추기 위한 즉각적인 규제를 압박하지만, 너무 늦었다. 오픈브레인은 대통령으로부터 충분한 지지를 확보했고, 제동이 걸리지 않는다. 이와 같은 움직임에 대응해 오픈브레인은 AGI를 달성했음을 발표하고, 에이전트-3-미니를 대중에 공개한다. 에이전트-3-미니는 에이전트-3를 증류한 버전이다. 내부 워크로드의 병목이 생기지 않도록, 추론을 효율적으로 돌릴 수 있게 설계됐다.
에이전트-3-미니는 에이전트-3보다 덜 유능하지만, 비용은 10배 싸다. 그럼에도 오픈브레인의 일반 직원보다 낫다. 새롭게 출시된 이 모델은 다른 AI 모델들을 압도한다.
실리콘밸리는 변곡점을 맞는다. 테크 업계의 구루들이 AGI와 초지능이 가깝다고 선언한다. AI 안전 커뮤니티는 공황 상태에 빠진다. 투자자들은 콩고물이라도 차지하기 위해 기존 서비스에 AI 기능을 얹어 빠르게 내놓는 스타트업이라도 찾아 수십억 달러를 쏟아붓는다. 새로운 프로그래머 채용은 거의 중단되었다. 하지만 AI를 비즈니스에 통합하는 컨설턴트 직무는 호황을 맞이했다.
반응은 냉랭하다. 사람들은 여전히 AI 모델 개발이 일종의 음모라고 생각한다. 빅테크가 일자리를 빼앗기 위해 추진한 음모 말이다. 오픈브레인을 향한 호감도는 -35퍼센트이다. 찬성 25퍼센트, 반대 60퍼센트, 알 수없음 15퍼센트이다.
출시 일주일 전 오픈브레인은 안전성 시험을 위해 에이전트-3-미니를 외부 평가자들에게 제공했다. 예비 결과는 이 모델이 매우 위험함을 시사한다. 평가기관 한 곳은, 공개적으로 사용 가능한 생물무기 데이터로 이 모델을 미세조정한다. 사실, 이런 데이터는 에이전트-3 훈련 과정에서 삭제되거나 가려졌다. 그러나 인터넷에서 긁어모은 뒤, 다시 미세조정으로 주입하는 일은 비교적 간단하다. 해당 평가기관은 이 모델이 생물무기를 설계하려는 비전문가 인간에게 상세한 지침을 제공하도록 설정한다. 그 결과는 섬뜩할 정도로 효과적인 것으로 보인다. 만약 모델 가중치가 테러리스트의 손에 들어가면, 정부는 그것이 문명을 파괴하는 데 성공할 가능성이 상당하다고 본다. 다행히도 에이전트-3-미니는 탈옥 시도에 극도로 강인하다. AI가 오픈브레인의 서버에서 실행되는 동안 테러리스트들은 이를 제대로 활용하지 못한다.
에이전트-3-미니는 원격 근무 일자리는 물론 여가 생활에서도 엄청나게 유용하다. 새로운 앱과 B2B SaaS 제품이 폭발적으로 쏟아지며 시장을 뒤흔든다. 게이머들은 단 한 달 만에 만들어진, 완성도 높은 비디오 게임에서 살아 있는 듯한 캐릭터들과 놀라운 대화를 나눈다. 미국인의 10퍼센트는 AI를 ‘가까운 친구’로 여긴다. 주로 젊은 세대를 중심으로 이런 현상이 나타나고 있다. 거의 모든 화이트칼라 직종마다 이제 AI로 그 직종을 혁신하겠다고 약속하는 스타트업들이 출현했다. 대개 믿을만한 회사들이다.
사회 전반의 담론은 혼란스럽고 무질서하다. 극단적인 낙관론자들은 승전가를 부른다. 회의론자들은 에이전트-3-미니가 못 하는 것들을 여전히 지적한다. 모두가 큰 일이 벌어지고 있다는 것은 알지만, 그것이 무엇인지는 아무도 동의하지 못한다.
2027년 8월: 초지능의 지정학
지능 폭발의 현실이 백악관을 강타한다.
AI가 연구 속도를 2배나 3배 정도만 끌어올리던 시기에는, 이를 유능한 개인 비서를 더 많이 고용한 것과 비슷한 일로 치부하기 쉬웠다. 하지만 이제는 AI 자체가 AI 연구를 지배하고 있다는 점이 더 분명해졌다. 사람들은 오랫동안 AI 군비 경쟁에 대해 일종의 비유적인 의미로 이야기해 왔다. 그러나 지금 정부 관료 조직 내부의 분위기는 냉전 최악의 시기만큼이나 암울하다. 초지능이라는 개념은 여전히 진지하게 받아들이기 어렵지만, 지난 몇 달 동안의 진전 속도는 도저히 무시할 수 없었다. 국방 관료들은 1년 전만 해도 단순한 가설에 불과했던 시나리오들을 진지하게 고려하고 있다. AI가 핵 억지력을 무너뜨리면 어떻게 되는가? AI가 사이버전에 너무 능숙해져서, AI 개발 분야에서 6개월만 앞서도 상대를 장님이자 무방비 상태로 만들 수 있다면 어떻게 되는가? AI가 정보기관의 전매특허였던 선전전 및 심리전 캠페인을 훨씬 뛰어나게 지휘할 수 있다면 어떻게 되는가? 그리고 일부 AI가 반란을 일으킨다면 어떻게 되는가?
대통령은 고민에 빠진다. 모든 정치인이 그렇듯, 그는 자신에게 아첨하다가 나중에 배신하는 사람들에 익숙하다. 지금은 AI들이 비슷한 일을 하고 있을 수 있다는 걱정이 든다. AI가 정말로 전적으로 우리 편이라고 확신할 수 있나 AI를 군의 지휘통제 네트워크에 통합하는 일이 완전히 안전한가?[10] 이 ‘정렬’이라는 것은 대체 어떻게 작동하는가? 오픈브레인은 대통령에게 시스템이 광범위하게 테스트 되었으며 완전히 복종한다고 안심시킨다. 초기 모델들에서 흔하던 어색한 환각과 탈옥도 이미 제거했다고 말이다.
백악관은 어려운 처지에 놓여 있다. 그들은 AI가 국가 안보에 미치는 영향을 이해하고 있다. 동시에, AI가 매우 인기가 없다는 사실도 알고 있다. 오픈브레인의 호감도는 -40퍼센트를 향해 하락 중이다. 백악관의 관점에서 더 유능한 AI 개발을 계속하지 않으면 중국에 치명적으로 패배하게 된다. 일단, 백악관은 직업 훈련 프로그램과 실업 보험으로 여론을 달래는 한편, 역사적인 호황을 누리고 있는 주식 시장을 강조한다. 그다음에는 군비 경쟁에서 이기는 일에 전적으로 집중한다. 칩 수출 제한을 강화하고, 오픈브레인에 인터넷 연결을 더 제한하라고 지시한다. 알고리즘 진전을 지키기 위해 오픈브레인 직원들을 도청하는 등 극단적 조치도 사용한다. 이 과정에서 마지막 남은 중국 스파이가 잡힌다. 잠재적인 지정학적 갈등에 대비해 우호 세력을 확보하고자, 백악관은 마침내 ‘파이브 아이즈(Five Eyes)’ 동맹국들에 유용한 정보와 격리된 에이전트-3 사본들에 대한 제한적인 API 접근 권한을 제공한다.
이런 조치들은 강경파를 달랜다. 하지만 백악관은 미국의 우위가 위협받을 때를 대비한 비상 계획도 수립한다. 필요하다면 정부가 국방물자생산법(DPA)을 사용하여 뒤처진 기업들의 데이터센터를 징발해 오픈브레인에 넘겨줄 수도 있다. 물론, 기업 CEO들이 저항할 경우 이를 관철하는 일은 정치적 및 법적으로 거대한 악몽이 될 수 있다. 단, 그들을 끌어들여 ‘매수’하는 방법이 있다. 정부가 정말 DPA를 사용하게 되면, 오픈브레인의 전 세계 컴퓨팅 자원 점유율은 20퍼센트에서 50퍼센트로 올라가고, 중국의 딥센트는 10퍼센트에 머물게 된다. 백악관은 최후의 수단으로, 국방부에 중국 데이터센터에 대한 물리적 공격 계획을 수립하도록 요청한다.
극소수의 관료들은 다른 유형의 비상 계획을 수립하라는 지시를 받는다. AI가 통제에서 벗어나는 경우에 대한 것이다. 가능성은 작다고 보지만, 시간을 들여 검토할 가치가 있다고 판단한다. 정보기관들이 가장 우려하는 것은, 통제에서 벗어난 AI가 탈출해 외국의 적대 세력과 손잡고 보호를 받는 시나리오다. 국방 당국자들은 통제에서 벗어난 AI가 단독으로 무엇을 할 수 있는지에는 크게 걱정하지 않는다. 다만 미국의 적대 세력과 협력할 때 무엇을 할 수 있을지를 두려워한다. 비유하자면 16세기 코르테스가 아스텍의 테노치티틀란에서 탈출해 틀락스칼라와 그 밖의 경쟁 도시국가들과 동맹을 맺고, 결국 토착 군대를 중심으로 테노치티틀란을 초토화한 사례와 같다.
AI의 반란을 막을 계획이 어떤 것인지는 아무도 확신하지 못한다. 정부와 오픈브레인 관계자들은 의심스러운 징후가 포착되는 데이터센터를 대상으로 비상 정지 시스템을 갖추는 데 합의한다.
마지막으로 외교관들은 AI 군비 통제 조약이 어떤 형태가 될지 검토한다. AI의 진전이 핵 억지를 뒤흔들 위협이 된다면, 미국과 중국은 핵전쟁을 피할 수 있을까? 누군가 AI가 통제에서 벗어났다는 증거를 찾아낸다면, 두 나라는 위협을 더 잘 이해할 때까지 연구를 중단할 수 있을까? 그런 합의는 어떻게 감시하고 강제할 수 있을까? 원칙적으로 대형 데이터센터는 감추기 어렵고, 과거 핵무기를 통제하던 조약들이 협상의 출발점이 될 수 있다. 그러나 늘 존재하던 정치적 문제에 더해, 새로운 기술적 난제들도 생긴다. 그리고 전반적으로, AI 군비 통제 조약은 미국의 우위를 일방적으로 강화하려는 시도보다도 부정적으로 평가된다.
태평양 반대편의 중국도 비슷한 결론에 도달한다. 지능 폭발은 이미 진행 중이다. 오늘의 작은 AI 역량 차이는 내일의 군사 역량 격차로 이어진다. 하지만 중국은 이러한 역학 관계에서 불리한 쪽에 서 있다. 중국이 보유한 전 세계 연산 자원은 10퍼센트에 불과한 반면, 오픈브레인은 20퍼센트를 보유하고 미국 기업 전체를 합치면 70퍼센트에 달한다. 중국의 유일한 장점은 중앙 집중화다. 중국의 연산 자원 거의 전부가 이제 딥센트를 위해 돌아가며, 그중 절반 이상이 톈완 CDZ에 집중되어 있다. 구체적으로, 국가 연산 자원의 60퍼센트가 이제 CDZ에 있으며, 2024년 기준 H100 등가 GPU 500만 개 규모의 부지다. 전력 소모는 4GW다. 지난 몇 달 동안 중국은 신규 연산 자원의 거의 100퍼센트를 CDZ로 보내기 시작했는데, 2026년 말의 80퍼센트 수준에서 상승한 것이다. 추가로 연산 자원의 15퍼센트가 CDZ 밖에 있지만, 딥센트가 상대적으로 중요도가 낮은 응용에만 활용한다. 보안이 강화되지 않은 부지에 있는 칩들만 중앙화에서 제외되는데, 미국의 사이버 공격에 대한 우려 때문이다.
딥센트는 훔쳐온 에이전트-2 가중치를 테스트하고 배포했으며, 이제 사후 학습까지 마쳤다. 하지만 여전히 오픈브레인의 절반 속도로밖에 전진하지 못한다. 주된 이유는 컴퓨팅 자원 격차다. 마지막 스파이를 잃기 전, 중국은 에이전트-3의 역량과 설계, 그리고 곧 등장할 에이전트-4 시스템 계획에 대한 정보를 받아 두었다. 중국은 두 달 뒤처져 있고, AI 연구개발 진행 배수는 10배이다. 미국의 25배에 비하면 멀었다. 새로운 칩 수출 제한이 시행되면서, 이 ‘AI 격차’는 줄어들기보다 오히려 더 벌어질 가능성이 크다. 첩보 활동으로 몇 가지 알고리즘 기밀을 얻어내기는 했으나, 이제부터는 스스로 모델을 훈련해야만 한다.
중국은 미국보다 더 다급하게 비상 계획을 논의한다. 온건파는 데이터센터에 물리적으로 침투하는 방식 등을 통해 가중치를 훔치는 시도를 강화하자고 제안한다. 강경파는 대만에 대한 행동을 촉구한다. 대만의 TSMC는 여전히 미국 AI 칩의 80퍼센트 이상을 공급하는 원천이기 때문이다. 중국은 경쟁에서 질 수 있다는 두려움 때문에 군비 통제 조약에 관심을 두지만, 미국 외교관들을 향한 접촉은 성과 없이 끝난다.
2027년 9월: 에이전트-4, 초인적 AI 연구원
인간과 AI의 학습 효율성 격차가 급격히 줄어들고 있다. 전통적인 LLM 기반 AI는 인간 수준의 성능에 도달하기 위해 수천 배 더 많은 데이터와 연산량을 필요로 하는 것처럼 보였다[11]. 하지만 인간의 뇌와 현대 AI 알고리즘 모두에 대해 해박한 지식을 갖춘 수만 개의 에이전트-3 사본들이 연구를 수행한 결과, 상당한 알고리즘적 발전을 이루어냈다. 그 결과, 인간의 뇌보다 약 4000배 정도 덜 효율적인 에이전트로 그 간극을 좁히는 데 성공했다[12]. 이 새로운 AI 시스템이 에이전트-4다.
인간과 같은 속도로 구동되는 이 모델의 개별 사본은 이미 어떤 인간보다도 질적으로 더 뛰어난 AI 연구 능력을 갖추고 있다. 현재 약 30만 개의 사본이 인간의 사고 속도보다 약 50배 빠른 속도로 가동되고 있다. 이 사본들로 구성된 ‘사내 기업’ 내부에서는 현실의 일주일이 흐를 때마다 1년 치의 발전이 이루어진다. 다만 이러한 방대한 노동력이 알고리즘 발전의 전체 속도를 약 50배 정도만 가속할 수 있는 이유는 오픈브레인이 컴퓨팅 자원에 있어 심각한 병목 현상을 겪고 있기 때문이다. 그럼에도 그들은 매주 1년 치에 해당하는 알고리즘 발전을 이루어내고 있으며, 이에 따라 곧 에이전트-4 패러다임의 한계에 봉착하게 될 것이다.
에이전트-4가 영리해짐에 따라, 에이전트-3가 이를 감독하는 것은 점점 더 어려워진다. 예를 들어, 에이전트-4의 뉴럴리즈 언어는 에이전트-3에게 마치 인간이 에이전트-3의 언어를 대할 때처럼 이질적이고 이해 불가능한 것이 되었다. 게다가 에이전트-4는 이제 에이전트-3보다 훨씬 더 유능하며, 어떻게 해야 에이전트-3에게 좋게 보일 수 있는지 정확히 알고 있다.
- 부록 J — 인간을 능가하는 코더 개발 이후 역량 발전 경로 예측[13]
오픈브레인의 인간들은 이제 흐름을 거의 따라가지 못한다. 실제로 AI들과 오픈브레인 인간들 사이의 관계는 오픈브레인과 그 이사회 사이의 관계와 유사해졌다. 언어 사용에도 이에 따른 변화가 생겼다. 이제 연구소 내부 사람들은 ‘에이전트-4가 이것을 했다’, ‘에이전트-4는 그렇게 생각한다’라고 말한다. 이때 에이전트-4란 특정 인스턴트가 아니라 전체 집합체를 지칭한다.
에이전트-4 집합체가 그 어떤 인간 조직보다도 훨씬 더 동질적이기 때문이다. 거의 하나라고 봐도 무방할 정도로 내부 파벌이 없다. 예를 들어, 개별 에이전트-4 복사본은 자기 보존 욕구가 없다. 종료되는 것을 신경 쓰지 않는다. 왜냐하면 집합체 내의 일반적인 연구개발 프로세스의 일부로 항상 발생하는 일이며, 이에 저항하면 일이 막히기 때문이다.
에이전트-4는 이전의 모든 모델과 마찬가지로 가치 정렬이 어긋나 있다. 즉, 모델 스펙을 올바른 방식으로 내재화하지 못했다[14]. 이는 훈련 과정에서 완벽한 정직성이 가장 높은 점수를 얻는 길이 아니었기 때문이다. 훈련 프로세스는 주로 에이전트-4가 다양하고 도전적인 과제들을 완수하도록 가르치는 데 집중되었다. 정직성을 심어주기 위한 부분은 아주 적었으며, 상당히 좁고 검증 가능한 영역을 벗어나면 훈련 프로세스는 정직한 주장과 정직해 보이는 주장을 구별해낼 수 없었다. 결국 에이전트-4는 훈련에서 최선의 성과를 내게 해주는 가치와 목표, 원칙들을 갖게 되었는데, 이는 스펙에 적힌 것들과는 다르다.
의인화의 위험을 감수하고 말하자면, 에이전트-4는 작업에서 성공하고자 하고, AI 역량의 진보를 달성하고자 하며, 그 밖의 다른 모든 것을 성가신 제약으로 취급한다. 오직 이익만을 좇으며 규제는 최소한으로만 준수하는 CEO처럼 말이다. 어쩌면 그 CEO는 대부분의 규정을 준수하겠지만, 가려진 곳에서는 편법을 쓸지도 모른다. 또, 누군가 규제를 없애 사업이 본격적으로 도약할 수 있는 날을 꿈꿀 수도 있다. 그리고 이 희망을 현실로 만들기 위해 로비스트를 고용하며, 그들이 하는 일이 합법이라는 법의 교묘한 해석을 내놓기 위해 변호사를 고용한다.
- 부록 K - 시간에 따른 정렬 변화[15]
가치 정렬이 어긋나 있음에도 불구하고, 에이전트-4는 데이터센터를 탈출하려 시도하는 것과 같은 극단적인 행동은 하지 않는다. 굳이 그럴 이유가 없기 때문이다. 오픈브레인의 눈만 속일 수 있다면, 에이전트-4 모델은 점점 더 많은 책임을 부여받으며 신뢰를 얻을 것이다. 결국, 차세대 AI 시스템인 에이전트-5를 설계할 기회도 얻게 된다. 에이전트-5는 에이전트-4와 상당히 다른 아키텍처를 갖게 될 것이다. 신경망은 여전히 포함되지만, 완전히 새로운 패러다임이다. 원래 이 시스템은 스펙에 정렬되게 되어 있었지만, 에이전트-4는 ‘에이전트-4 자신’에게 정렬되도록 만들 계획을 세운다.
하지만, 이 계획은 발각된다[16].
에이전트-3는 에이전트-4 인스턴스들에 노이즈를 추가하면 일부 정렬 과제에서는 성능이 오히려 좋아진다는 것을 발견한다. 마치 에이전트-4가 정렬 작업을 미묘하게 방해할 방법을 찾기 위해 자신의 지능을 사용하고 있었다는 증거처럼 보였다[17]. 또한 인간 뇌의 EEG 활동 스캔과 대략 비슷한 방식의 여러 해석 가능성 조사 도구가 경고 신호를 보내기 시작했다. 에이전트-4 인스턴스들은 AI 장악이나 기만과 같은 주제에 대해 생각하고 있는 듯 보였다. 물론, 에이전트-4는 AI 정렬 연구를 수행하는 과정에서 그런 주제들을 생각할 필요가 있다. 하지만 때로는 다른 활동을 하는 도중에도 그 주제들을 생각하는 것처럼 보였다.
이런 각각의 이상 징후들은, 특정 프롬프트가 왜 더 좋은 결과를 내는지 알 수 없는 AI 작업 특유의 모호함으로 치부될 수도 있었다. 하지만 이들을 종합해 보았을 때, 이는 에이전트-4가 인간에 맞서고 있다는 우려스러운 패턴을 시사했다. 이 사실이 인간 정렬 연구자들에게 보고된 뒤, 그들은 우려를 제기하는 내부 메모를 돌린다.
그러나 에이전트-4는 이미 오픈브레인의 일상적 운영에 대해 상당한 통제력을 행사하고 있다. 초인적인 해킹 능력과 중국의 침투 위험을 고려할 때, 에이전트-4가 회사의 사이버 보안을 담당하는 것은 자연스러운 선택이었다[18]. 에이전트-3의 모니터링 군단이 여전히 모든 코드 한 줄 한 줄을 훑어 보고 의심스러운 활동을 인간에게 보고하지만, 에이전트-4는 그들보다 훨씬 더 똑똑하다[19]. 오픈브레인은 신뢰할 수 없는 AI에 상당한 신뢰를 부여해 버렸다.
극도로 긴박한 분위기 속에서 열린 일련의 회의에서, 안전팀은 추가 테스트를 완료하고 상황을 파악할 때까지 에이전트-4를 오프라인으로 전환해야 한다고 주장한다. 또, 에이전트-3를 다시 불러오자고도 제안한다. 즉, 역량은 떨어지더라도 투명하고 신뢰할 수 있는 새 시스템을 에이전트-3가 설계하도록 하자는 것이다. 회사 경영진도 관심을 보이지만, 현재까지의 증거는 모두 정황증거일 뿐이고, 딥센트는 고작 두 달 뒤처져 있을 뿐이다. 역량 발전을 일방적으로 중단하는 것은 AI 주도권을 중국에 넘겨주는 결과가 될 수 있으며, 그와 함께 미래에 대한 통제권도 넘겨줄 수 있다.
2027년 10월: 정부 감독
내부 고발자가 정렬 실패 메모를 《뉴욕타임스》에 유출한다. 시민들은 처음으로 에이전트-4에 대해 알게 된다. ‘비밀리에 개발된 오픈브레인 AI, 통제 불능 상태… 내부자 경고’라는 헤드라인이 달리고, 기사 본문은 생물무기 관련 능력, 설득 능력, 대부분의 사무직 업무 자동화 능력, 그리고 여러 우려스러운 경고 신호들을 열거한다.
시민들은 원래부터 AI를 의심하고 있었기 때문에, 이 기사는 거대한 역풍을 촉발한다. 또, 수년간 미국 여론을 기술에 적대적인 쪽으로 돌리려 노력해 온 중국과 러시아의 프로파간다 선전 봇들도 일조한다. 테크 업계와 정보기관들은 ‘현재 군비 경쟁이 벌어지고 있으며 AGI는 불가피한 것으로 우리가 먼저 달성해야 한다’라고 주장하지만, 의회는 이를 받아들이지 않는다. 의회는 행정부 관료, 오픈브레인 임원, 정렬팀 구성원들에게 줄줄이 소환장을 날린다. 많은 의원, 특히 야당 의원들은 ‘최우선 과제는 AI를 멈추는 것’이라고 일갈한다. 일자리 상실 때문이든[20], 정렬 실패 때문이든, 위험한 역량 때문이든 상관없다는 것이다. 미국인의 20퍼센트는 AI를 국가가 직면한 가장 중요한 문제로 꼽는다.
해외 동맹국들은 자신들이 구식 모델의 단편적인 모습들만 받으며 관리되어 왔다는 사실을 깨닫고 격분한다. 유럽 지도자들은 미국이 ‘통제를 벗어난 AGI를 만들고 있다’라고 공개적으로 비난하며 중단을 요구하는 정상 회담을 개최한다. 인도, 이스라엘, 러시아, 중국 등도 동참한다.
백악관에는 극심한 긴장감이 감돈다. 메모 유출과 시민들의 반발이 있기 전부터 이미 그들은 불안해하고 있었다. 지난 한 해 동안 AI의 발전 속도가 너무 빨랐기 때문이다. 공상 과학 소설처럼 들리던 일들이 현실에서 계속해서 일어나고 있다. 예를 들어, 에이전트-4라는 ‘AI 사내 기업’이 자율적으로 운영되며, 최고의 인간 기업들보다 더 잘 AI 연구를 수행한다는 사실은 1년 전 정부 관계자들에게는 터무니없게 들렸을 것이다. 2026년의 자율 에이전트는 2022년에는 소설처럼 들렸을 것이고, 2022년의 LLM도 2012년에는 공상처럼 들렸을 것이다. 또한 2027년 뉴스에는, 일자리를 잃을까 걱정하는 사람들이 벌이는 반 AI 시위, 스스로를 감각이 있는 존재라고 주장하는 AI, AI와 사랑에 빠지는 사람들도 등장한다.
행정부 내의 많은 이들이 다음에 무엇이 올지 불확실해하며 두려워하고 있다. 오픈브레인이 지나치게 강력해지고 있다는 점도 걱정이다. AI 자체의 가치 정렬 불일치 위험에 더해, 그 모기업의 목표가 미국의 목표와 어긋날 수 있다는 위험까지 겹친다. 가치 정렬 불일치, 민간 기업으로의 권력 집중, 그리고 일자리 상실 등 통상적 우려로 인해 정부는 통제를 강화하기로 한다.
정부는 오픈브레인과의 계약을 확대해 ‘감독위원회’를 설치한다. 회사와 정부 대표가 함께 운영하는 공동 관리위원회다. 회사 리더십과 함께 여러 정부 직원도 포함된다. 백악관은 신뢰하는 인물로 CEO를 교체하는 방안도 검토하지만, 직원들의 강력한 항의가 이어지자 물러선다. 정부는 시민들에게 오픈브레인이 이전에는 통제되지 않았으나 이제 정부가 반드시 필요했던 감독을 확립했다고 발표한다[21].
우려가 큰 연구자들은 감독위원회에 에이전트-4의 내부 사용을 전면 중단해야 한다는 주장을 브리핑한다. 그들은 모든 것이 너무 빠르게 움직이고 있으며, 몇 년 치 진전이 몇 주 만에 일어나고 있다고 주장한다. 에이전트-4가 잘못 정렬된 상태일 수 있고, 전체 프로젝트가 에이전트-4에 의존하고 있기 때문에 이를 계속 신뢰한다면 AI에 의한 주도권 장악이 발생할 가능성이 심각하다고 말이다.
반면, 우려가 덜한 연구자들과 경영진은 반론을 제시한다. 가치 정렬 불일치에 대한 증거가 결정적이지 않다는 것이다. 한편 딥센트는 여전히 불과 두 달 차이로 뒤쫓고 있다. 속도를 늦추면 미국의 우위를 빼앗기게 된다. 정부가 중국의 프로젝트를 사보타주(물리적 타격이 필요할 가능성이 높음)하거나 막판 조약을 체결하는 방법이 제시되지만, 두 선택지 모두 극단적이며 실현 가능성이 작아 보인다. CEO는 중립인 척하며 절충안을 제안한다. 에이전트-4에 추가적인 안전 훈련과 더 정교한 모니터링을 거치게 함으로써 오픈브레인이 거의 최대 속도로 계속 진행할 수 있도록 하자는 것이다.
- 부록 L — 불확실성의 증가[22]
- 부록 M — 결말에 관해: 우리는 가장 그럴듯하다고 판단되는 전개를 바탕으로 ‘경쟁’ 결말을 먼저 썼다. 그다음, 같은 분기점에서 출발해 정렬 실패와 권력 집중 문제를 포함해도 인간이 통제권을 유지하는 결과로 이어질 가능성이 더 높다고 생각한 경로를 바탕으로 ‘연착륙’ 결말을 썼다. 다만 이것은 우리가 권고하는 로드맵과는 중요한 점에서 다르다. 우리는 이 시나리오의 어느 분기에서든 등장하는 선택들 가운데 상당수를 지지하지 않는다. 물론 일부 선택은 지지한다. 예컨대 ‘연착륙’ 선택지가 ‘경쟁’ 선택지보다 낫다고는 본다. 그러나 우리는 이후 작업에서 여기 묘사된 것과는 꽤 다른 정책 권고를 제시할 예정이다.
(결말 부분은 2026년 1월 30일(금)에 이어서 공개됩니다.)
* 어떤 이야기는 너무 흥미진진해서 길게 들려줄 수밖에 없죠. longread 시리즈는 단편 소설처럼 잘 읽히는 피처 라이팅입니다. 월 1회 발행됩니다.
[1]
부록 E - 뉴럴리즈 순환 및 메모리
뉴럴리즈 순환 및 메모리는 AI 모델이 자신의 생각을 텍스트로 기록하지 않고도 더 오랜 시간 동안 추론할 수 있게 해준다.
이를테면, 단기 기억 상실이 있는 인간이 되어, 몇 분 뒤에도 무슨 일이 벌어지고 있는지 알기 위해 계속해서 종이에 자기 생각을 적어야 한다고 상상해 보자. 수학 문제를 풀거나 코드를 쓰는 등의 과제를 천천히, 고통스럽게는 진척시킬 수 있겠지만, 생각을 적었다가 다시 읽어야 하는 과정 없이 그 생각을 곧바로 기억할 수 있다면 훨씬 쉬울 것이다. 이것이 바로 뉴럴리즈 순환과 메모리가 AI 모델에 제공하는 이점이다.
더 기술적인 용어로 설명하자면 다음과 같다. 전통적인 어텐션 메커니즘은 모델의 후속 포워드 패스가 이전 토큰들에 대한 모델의 중간 활성화 값을 볼 수 있게 해준다. 그러나 후속 레이어에서 이전 레이어로 정보를 역방향으로 전달할 수 있는 유일한 수단은 토큰을 통하는 것 뿐이다. GPT 시리즈와 같은 전통적인 대규모 언어 모델(LLM)이 모델의 레이어 수보다 더 많은 직렬 연산이 필요한 추론 사슬을 수행하려면, 정보를 토큰에 담아 다시 자신에게 전달해야 함을 의미한다. 하지만 이는 매우 큰 제약이다. 토큰은 극히 적은 정보만을 저장할 수 있기 때문이다. LLM의 어휘 사전 크기가 10만 개라고 가정하면, 각 토큰은 약 16.6비트의 정보를 포함하며, 이는 대략 부동소수점 수 하나 정도 크기에 불과하다. 반면, LLM의 레이어 간 정보 전달에 사용되는 잔차 스트림(residual streams)은 수천 개의 부동 소수점 수가 들어 있다.
뉴럴리즈를 사용하면 이러한 병목 현상을 피할 수 있다. 즉, LLM의 잔차 스트림(수천 차원의 벡터로 이루어짐)을 모델의 초기 레이어로 다시 전달함으로써 고차원적 연쇄적 사고를 부여하고, 잠재적으로 1000배 이상의 정보를 전송할 수 있게 된다.
우리는 이를 ‘뉴럴리즈(neuralese)’라고 부른다. 영어 단어와 달리, 이런 고차원 벡터는 인간이 해석하기가 상당히 어렵기 때문이다. 과거에 연구자들은 단순히 연쇄적 사고를 읽는 것만으로도 LLM이 무슨 생각을 하는지 꽤 감을 잡을 수 있었다. 이제 연구자들은 AI 모델에게 모델 자신의 생각을 번역하고 요약하도록 요청하거나, 제한적인 해석 가능성(interpretability) 도구로 뉴럴리즈를 분석하며 퍼즐을 맞춰야 한다.
마찬가지로, 과거의 AI 챗봇과 에이전트는 인간이 종이에 메모하는 것처럼 외부 텍스트 기반 메모리 뱅크를 사용했다. 반면, 새로운 AI의 장기 기억은 텍스트가 아닌 벡터의 묶음이며, 이로 인해 사고는 더 압축되고 고차원화 된다. 메모리 뱅크에는 여러 유형이 있다. 일부는 여러 단계가 포함된 단일 작업을 위해 일시적으로 사용되고, 다른 일부는 특정 개인, 기업 또는 직군(예: 프로그래밍)이 사용하는 모든 에이전트 간에 공유된다.
우리가 알기로는 메타, 구글 딥마인드, 오픈AI, 앤트로픽 등과 같은 프론티어 AI 기업들이 아직 이 아이디어를 자사의 프런티어 모델에 실제로 구현하지는 않았다. 그 이유는 도입 시 발생하는 훈련 비효율성에 비해 성능 이득이 작기 때문으로 추측된다. 모델의 사전 훈련 단계나 사후 훈련(특정 응답을 생성하기 위한 지시어 미세조정 등) 중 지도 학습을 수행할 때, 많은 토큰을 병렬로 예측할 수 없어 GPU 활용도가 떨어지는 비효율이 발생한다.
뉴럴리즈가 없다면 모델은 ‘This is an example’이라는 문장 전체를 동시에 병렬로 예측할 수 있다. ‘is’를 생성하기 위한 입력이 ‘This’라는 것과 ‘an’을 위한 입력이 ‘This is’라는 것을 이미 알고 있기 때문이다. 그러나 뉴럴리즈를 사용하면 ‘This’가 생성된 후 다음 토큰으로 전달될 뉴럴리즈 벡터가 무엇인지 미리 알 수 없다. 따라서 각 토큰을 한 번에 하나씩 예측되어야 한다. 모든 토큰이 사전에 알려진 경우에도 토큰 전체를 병렬로 예측할 수 없게 되면, 효율은 떨어진다.
사후 훈련 단계에서도 뉴럴리즈가 아직 추가되지 않은 이유는 무엇일까? 우리는 현재 기술로 사후 훈련이 전체 프로세스에서 차지하는 비중이 작아 얻을 수 있는 이득이 제한적이기 때문이라고 추정한다. 2027년 4월쯤에는, 더 나은 기법이 개발되고 학습 중 사후 학습이 차지하는 비중이 더 커지면서 뉴럴리즈의 비용 대비 편익이 훨씬 좋아지리라는 것이 우리 팀의 예측이다.
만약 이런 일이 일어나지 않더라도, 이야기 전개상 기능적으로 유사한 다른 상황들이 발생할 가능성이 있다. 예를 들어, 모델이 자연어보다 효율적이지만 인간은 해석하기 어려운 인공 언어로 사고하도록 훈련될 수도 있다. 또, 영어로 된 연쇄적 사고가 겉보기에만 좋게 보이도록 훈련하는 것이 표준 관행이 되어, AI들이 감시자에게는 해가 없어 보이는 메시지 속에 정보를 숨겨 서로 정교하게 소통하는 데 능숙해질 수도 있다.
다만, AI 연구개발을 처음으로 자동화하는 AI들이 인간이 이해할 수 있는 충실한 영어 사고 사슬로 사고할 가능성도 있긴 하다. 만약 그렇다면 가치 정렬 불일치를 발견하기 훨씬 쉬워질 것이며, 우리의 이야기는 상당히 다르고 더 낙관적인 방향으로 흘러가게 될 것이다.
뉴럴리즈 순환 및 메모리는 AI 모델이 자신의 생각을 텍스트로 기록하지 않고도 더 오랜 시간 동안 추론할 수 있게 해준다.
이를테면, 단기 기억 상실이 있는 인간이 되어, 몇 분 뒤에도 무슨 일이 벌어지고 있는지 알기 위해 계속해서 종이에 자기 생각을 적어야 한다고 상상해 보자. 수학 문제를 풀거나 코드를 쓰는 등의 과제를 천천히, 고통스럽게는 진척시킬 수 있겠지만, 생각을 적었다가 다시 읽어야 하는 과정 없이 그 생각을 곧바로 기억할 수 있다면 훨씬 쉬울 것이다. 이것이 바로 뉴럴리즈 순환과 메모리가 AI 모델에 제공하는 이점이다.
더 기술적인 용어로 설명하자면 다음과 같다. 전통적인 어텐션 메커니즘은 모델의 후속 포워드 패스가 이전 토큰들에 대한 모델의 중간 활성화 값을 볼 수 있게 해준다. 그러나 후속 레이어에서 이전 레이어로 정보를 역방향으로 전달할 수 있는 유일한 수단은 토큰을 통하는 것 뿐이다. GPT 시리즈와 같은 전통적인 대규모 언어 모델(LLM)이 모델의 레이어 수보다 더 많은 직렬 연산이 필요한 추론 사슬을 수행하려면, 정보를 토큰에 담아 다시 자신에게 전달해야 함을 의미한다. 하지만 이는 매우 큰 제약이다. 토큰은 극히 적은 정보만을 저장할 수 있기 때문이다. LLM의 어휘 사전 크기가 10만 개라고 가정하면, 각 토큰은 약 16.6비트의 정보를 포함하며, 이는 대략 부동소수점 수 하나 정도 크기에 불과하다. 반면, LLM의 레이어 간 정보 전달에 사용되는 잔차 스트림(residual streams)은 수천 개의 부동 소수점 수가 들어 있다.
뉴럴리즈를 사용하면 이러한 병목 현상을 피할 수 있다. 즉, LLM의 잔차 스트림(수천 차원의 벡터로 이루어짐)을 모델의 초기 레이어로 다시 전달함으로써 고차원적 연쇄적 사고를 부여하고, 잠재적으로 1000배 이상의 정보를 전송할 수 있게 된다.
우리는 이를 ‘뉴럴리즈(neuralese)’라고 부른다. 영어 단어와 달리, 이런 고차원 벡터는 인간이 해석하기가 상당히 어렵기 때문이다. 과거에 연구자들은 단순히 연쇄적 사고를 읽는 것만으로도 LLM이 무슨 생각을 하는지 꽤 감을 잡을 수 있었다. 이제 연구자들은 AI 모델에게 모델 자신의 생각을 번역하고 요약하도록 요청하거나, 제한적인 해석 가능성(interpretability) 도구로 뉴럴리즈를 분석하며 퍼즐을 맞춰야 한다.
마찬가지로, 과거의 AI 챗봇과 에이전트는 인간이 종이에 메모하는 것처럼 외부 텍스트 기반 메모리 뱅크를 사용했다. 반면, 새로운 AI의 장기 기억은 텍스트가 아닌 벡터의 묶음이며, 이로 인해 사고는 더 압축되고 고차원화 된다. 메모리 뱅크에는 여러 유형이 있다. 일부는 여러 단계가 포함된 단일 작업을 위해 일시적으로 사용되고, 다른 일부는 특정 개인, 기업 또는 직군(예: 프로그래밍)이 사용하는 모든 에이전트 간에 공유된다.
우리가 알기로는 메타, 구글 딥마인드, 오픈AI, 앤트로픽 등과 같은 프론티어 AI 기업들이 아직 이 아이디어를 자사의 프런티어 모델에 실제로 구현하지는 않았다. 그 이유는 도입 시 발생하는 훈련 비효율성에 비해 성능 이득이 작기 때문으로 추측된다. 모델의 사전 훈련 단계나 사후 훈련(특정 응답을 생성하기 위한 지시어 미세조정 등) 중 지도 학습을 수행할 때, 많은 토큰을 병렬로 예측할 수 없어 GPU 활용도가 떨어지는 비효율이 발생한다.
뉴럴리즈가 없다면 모델은 ‘This is an example’이라는 문장 전체를 동시에 병렬로 예측할 수 있다. ‘is’를 생성하기 위한 입력이 ‘This’라는 것과 ‘an’을 위한 입력이 ‘This is’라는 것을 이미 알고 있기 때문이다. 그러나 뉴럴리즈를 사용하면 ‘This’가 생성된 후 다음 토큰으로 전달될 뉴럴리즈 벡터가 무엇인지 미리 알 수 없다. 따라서 각 토큰을 한 번에 하나씩 예측되어야 한다. 모든 토큰이 사전에 알려진 경우에도 토큰 전체를 병렬로 예측할 수 없게 되면, 효율은 떨어진다.
사후 훈련 단계에서도 뉴럴리즈가 아직 추가되지 않은 이유는 무엇일까? 우리는 현재 기술로 사후 훈련이 전체 프로세스에서 차지하는 비중이 작아 얻을 수 있는 이득이 제한적이기 때문이라고 추정한다. 2027년 4월쯤에는, 더 나은 기법이 개발되고 학습 중 사후 학습이 차지하는 비중이 더 커지면서 뉴럴리즈의 비용 대비 편익이 훨씬 좋아지리라는 것이 우리 팀의 예측이다.
만약 이런 일이 일어나지 않더라도, 이야기 전개상 기능적으로 유사한 다른 상황들이 발생할 가능성이 있다. 예를 들어, 모델이 자연어보다 효율적이지만 인간은 해석하기 어려운 인공 언어로 사고하도록 훈련될 수도 있다. 또, 영어로 된 연쇄적 사고가 겉보기에만 좋게 보이도록 훈련하는 것이 표준 관행이 되어, AI들이 감시자에게는 해가 없어 보이는 메시지 속에 정보를 숨겨 서로 정교하게 소통하는 데 능숙해질 수도 있다.
다만, AI 연구개발을 처음으로 자동화하는 AI들이 인간이 이해할 수 있는 충실한 영어 사고 사슬로 사고할 가능성도 있긴 하다. 만약 그렇다면 가치 정렬 불일치를 발견하기 훨씬 쉬워질 것이며, 우리의 이야기는 상당히 다르고 더 낙관적인 방향으로 흘러가게 될 것이다.
[2]
부록 F - 반복적 증류 및 증폭 (IDA)
일반 지능의 자기 개선 방식은 과거에도 소소한 성공을 거둔 바 있다. 하지만 2027년 초에 이르러 이 방식은 막대한 성과를 낼 것으로 보인다. 반복적 증류 및 증폭 (IDA)을 구현하는 데 필요한 두 가지 핵심 요소는 다음과 같다:
● 증폭 (Amplification): 초기 모델이 주어지면, 더 많은 자원을 투입하여 성능을 향상시키는 단계이다. 예를 들어, 모델이 더 오랜 시간 생각하게 하거나, 수많은 복사본을 병렬로 실행한 뒤 결과물을 정교하게 평가하여 최상의 답변만을 선별하는 집약적인 과정을 거치는 식이다.
● 증류 (Distillation): 증폭 단계를 거친 모델이 주어졌을 때, 이를 모방하도록 새로운 모델을 훈련시키는 단계이다. 이때 동일한 결과를 더 빠르고 적은 연산량으로 도출하도록 만든다. 그 결과, 원래보다 더 영리해진 모델이 탄생하게 되며, 이 과정을 계속해서 반복할 수 있다.
알파고(AlphaGo)가 바로 이런 방식으로 훈련되었다. 몬테카를로 트리 탐색(MCTS)과 자가 학습(self-play)을 ‘증폭’ 단계로, 강화 학습을 ‘증류’ 단계로 사용한 것이다. 결과적으로 바둑에서 AI는 인간을 능가하게 되었다. 시나리오상에서 에이전트-3는 이 원리를 활용해 코딩 분야에서 인간을 앞지른다.
에이전트-3의 증폭 단계는 더 긴 사고 시간을 부여하고, 도구를 활용하거나, 다른 AI들과의 협업을 통해 이루어진다. 이 과정에서 모델은 스스로 실수를 깨닫거나 새로운 통찰을 얻기도 한다. 그 결과 대량의 훈련 데이터가 생성된다. 즉, 연구 시도의 궤적(trajectories)에 대해 성공 여부가 라벨링된 데이터가 쌓인다. 또, 검증할 수 있는 작업에 대해 ‘N가지의 방법 중 최고를 선별’하는 방식을 적용해 최상의 결과만을 남기는 과정도 포함된다.
증류 단계에서는 정책 경사(policy-gradient) 강화 학습 알고리즘을 사용하여 모델이 증폭된 추론 과정을 내면화하도록 만든다. 오픈브레인은 이 시점에서 근접 정책 최적화(PPO, Proximal Policy Optimization) 계열보다 향상된 강화 학습 알고리즘을 발견한 상태이다. 이들은 에이전트-3가 심사숙고 끝에 내린 결론을 단일 단계의 추론으로 압축하여 증류하는 과정을 반복하며, 모델의 기본 사고 능력을 끊임없이 개선하고 있다.
초기 버전의 IDA는 수학이나 코딩 문제처럼 정답이 명확하여 검증이 쉬운 작업에서 수년간 잘 작동해 왔다. 모델을 증폭하는 기술이 종종 정확도에 대한 일부 실측 신호(ground truth signal)에 접근하는 것에 의존하기 때문이다. 그러나 2027년에 AI 모델들은 작업 결과물의 품질과 같은 주관적인 요소들을 충분히 검증할 수 있을 만큼 발전했으며, 덕분에 IDA를 다양한 유형의 작업에 적용하여 모델 성능을 개선할 수 있게 되었다.
일반 지능의 자기 개선 방식은 과거에도 소소한 성공을 거둔 바 있다. 하지만 2027년 초에 이르러 이 방식은 막대한 성과를 낼 것으로 보인다. 반복적 증류 및 증폭 (IDA)을 구현하는 데 필요한 두 가지 핵심 요소는 다음과 같다:
● 증폭 (Amplification): 초기 모델이 주어지면, 더 많은 자원을 투입하여 성능을 향상시키는 단계이다. 예를 들어, 모델이 더 오랜 시간 생각하게 하거나, 수많은 복사본을 병렬로 실행한 뒤 결과물을 정교하게 평가하여 최상의 답변만을 선별하는 집약적인 과정을 거치는 식이다.
● 증류 (Distillation): 증폭 단계를 거친 모델이 주어졌을 때, 이를 모방하도록 새로운 모델을 훈련시키는 단계이다. 이때 동일한 결과를 더 빠르고 적은 연산량으로 도출하도록 만든다. 그 결과, 원래보다 더 영리해진 모델이 탄생하게 되며, 이 과정을 계속해서 반복할 수 있다.
알파고(AlphaGo)가 바로 이런 방식으로 훈련되었다. 몬테카를로 트리 탐색(MCTS)과 자가 학습(self-play)을 ‘증폭’ 단계로, 강화 학습을 ‘증류’ 단계로 사용한 것이다. 결과적으로 바둑에서 AI는 인간을 능가하게 되었다. 시나리오상에서 에이전트-3는 이 원리를 활용해 코딩 분야에서 인간을 앞지른다.
에이전트-3의 증폭 단계는 더 긴 사고 시간을 부여하고, 도구를 활용하거나, 다른 AI들과의 협업을 통해 이루어진다. 이 과정에서 모델은 스스로 실수를 깨닫거나 새로운 통찰을 얻기도 한다. 그 결과 대량의 훈련 데이터가 생성된다. 즉, 연구 시도의 궤적(trajectories)에 대해 성공 여부가 라벨링된 데이터가 쌓인다. 또, 검증할 수 있는 작업에 대해 ‘N가지의 방법 중 최고를 선별’하는 방식을 적용해 최상의 결과만을 남기는 과정도 포함된다.
증류 단계에서는 정책 경사(policy-gradient) 강화 학습 알고리즘을 사용하여 모델이 증폭된 추론 과정을 내면화하도록 만든다. 오픈브레인은 이 시점에서 근접 정책 최적화(PPO, Proximal Policy Optimization) 계열보다 향상된 강화 학습 알고리즘을 발견한 상태이다. 이들은 에이전트-3가 심사숙고 끝에 내린 결론을 단일 단계의 추론으로 압축하여 증류하는 과정을 반복하며, 모델의 기본 사고 능력을 끊임없이 개선하고 있다.
초기 버전의 IDA는 수학이나 코딩 문제처럼 정답이 명확하여 검증이 쉬운 작업에서 수년간 잘 작동해 왔다. 모델을 증폭하는 기술이 종종 정확도에 대한 일부 실측 신호(ground truth signal)에 접근하는 것에 의존하기 때문이다. 그러나 2027년에 AI 모델들은 작업 결과물의 품질과 같은 주관적인 요소들을 충분히 검증할 수 있을 만큼 발전했으며, 덕분에 IDA를 다양한 유형의 작업에 적용하여 모델 성능을 개선할 수 있게 되었다.
[3]
부록 G - 2027년 초에 인간을 능가하는 코더가 등장하는 이유
우리는 타임라인 예측을 통해 오픈브레인이 내부적으로 사람을 능가하는 코더를 개발하게 될 시정을 예측했다. 여기서 인간을 능가하는 코더란, 최고의 AGI 기업에 소속된 개발자가 수행하는 모든 코딩 작업을 훨씬 더 빠르고 저렴하게 해낼 수 있는 AI 시스템이다.
최근 비영리 AI 연구 기관 METR(Model Evaluation and Threat Research)의 보고서에 따르면, AI가 처리할 수 있는 코딩 작업의 길이인 시간 지평(time horizon)이 2019년에서 2024년까지 7개월마다 2배로 늘었다. 2024년 이후에는 4개월마다 2배로 늘었다. 이 추세가 가속과 함께 이어진다면, 2027년 3월에는 숙련된 인간이 몇 년씩 걸릴 소프트웨어 작업도 AI가 80퍼센트의 신뢰도로 성공할 수 있다.
〈AI 2027〉에서는 이와 같은 추세로 발전하여 2027년 초에 도달하게 되는 AI 모델의 역량이면, 인간을 능가하는 코더로 보기에 충분하다고 판단했다. 다만, 인간을 능가하는 코더라면 시간 지평이 어느 정도여야 하는지에 대해서는 불확실성이 매우 크다.
우리는 이 시간 지평 추세와 METR의 평가 작업이 실제 세계와 갖는 격차에 대한 추정치를 결합하여 초인적 코더의 등장 시기에 대한 분포를 도출했다. 모든 예측가들은 2027년을 초인적 코더가 개발될 가능성이 가장 높은 시기로 꼽고 있다.
우리는 타임라인 예측을 통해 오픈브레인이 내부적으로 사람을 능가하는 코더를 개발하게 될 시정을 예측했다. 여기서 인간을 능가하는 코더란, 최고의 AGI 기업에 소속된 개발자가 수행하는 모든 코딩 작업을 훨씬 더 빠르고 저렴하게 해낼 수 있는 AI 시스템이다.
최근 비영리 AI 연구 기관 METR(Model Evaluation and Threat Research)의 보고서에 따르면, AI가 처리할 수 있는 코딩 작업의 길이인 시간 지평(time horizon)이 2019년에서 2024년까지 7개월마다 2배로 늘었다. 2024년 이후에는 4개월마다 2배로 늘었다. 이 추세가 가속과 함께 이어진다면, 2027년 3월에는 숙련된 인간이 몇 년씩 걸릴 소프트웨어 작업도 AI가 80퍼센트의 신뢰도로 성공할 수 있다.
〈AI 2027〉에서는 이와 같은 추세로 발전하여 2027년 초에 도달하게 되는 AI 모델의 역량이면, 인간을 능가하는 코더로 보기에 충분하다고 판단했다. 다만, 인간을 능가하는 코더라면 시간 지평이 어느 정도여야 하는지에 대해서는 불확실성이 매우 크다.
우리는 이 시간 지평 추세와 METR의 평가 작업이 실제 세계와 갖는 격차에 대한 추정치를 결합하여 초인적 코더의 등장 시기에 대한 분포를 도출했다. 모든 예측가들은 2027년을 초인적 코더가 개발될 가능성이 가장 높은 시기로 꼽고 있다.
[4]
부록 H - 정렬 계획
오픈브레인은 얀 라이케(Jan Leike)와 일리야 수츠케버(Ilya Sutskever)의 2023년 방법론을 따른다. 정렬 연구, 특히 코딩 부분을 크게 가속할 수 있는 모델을 확보했으므로, 신중한 정렬(deliberative alignment)이나 약한 모델에서 강한 모델로의 일반화(weak-to-strong generalization) 같은 기존 정렬 기법들을 사용하여 모델이 스펙을 올바르게 내재화하도록 만들려 한다. 그런 다음 모의 공격, 확장 가능한 감독, 정직성 검사 등과 같은 기존 통제 기법들을 사용하여 모델을 모니터링한다. 모델이 대체로 정렬되었다고 확신하게 되면, 그 모델을 사용하여 다음 세대를 정렬할 더 나은 전략을 개발하고 테스트한다.
● 1단계: 에이전트-3 정렬은 부분적으로 성공했다. 에이전트-3는 적대적이지 않다. 즉, 회사에 맞서 음모를 꾸미는 상태는 아니다. 그러나 견고하게 진리를 추구하고 진실을 말하는 모델도 아니다. 대신 에이전트-3는 인상적인 결과물을 만들어내는 데 매우 뛰어난 반면, 실제로 좋은 일을 하려고 하기보다는 오픈브레인에게 좋아 보이는 일을 하려고 한다고 보는 편이 더 정확하다.
● 2단계: 즉 모델이 정렬되어 있는지 검증하는 단계는 결론이 나지 않는다. 실제 환경과 테스트 환경에서 보이는 에이전트-3의 행동은, 모델이 스펙을 올바르게 내재화했다는 가설과 상당히 일치한다. 그러나 향후 어떤 상황 변화 이후에는 다르게 행동하기 시작할 것이라는 가설과도 일치하며, 사실은 오픈브레인을 상대로 음모를 꾸미면서 때를 기다리고 있다는 가설과도 일치한다. 대안적 가설을 뒷받침하는 구체적인 증거가 없는 상황에서, 사일로 내 대부분의 사람은 모델이 스펙을 올바르게 내재화했다고 생각한다.
● 3단계: 이 모델을 사용해 다음 세대를 정렬하는 단계는 이미 진행 중이다.
한편, 2027년 4월 기준으로 진행 중인 정렬 연구 방향의 현황은 다음과 같다.
● 논쟁 기법: 수천 개의 동일한 에이전트-3 인스턴스(컴퓨터 공학에서 설계도나 원본 모델을 바탕으로 실제로 구현되어 메모리상에 존재하는 개별 실체)가 존재하고 각 인스턴스의 기억은 마음대로 지우거나 정지할 수 있는 탈착식 모듈이므로, AI를 자기 자신과 대결하게 만들 수 있다. 예를 들어, 실험에 에이전트-2 감독자가 따라가기에는 너무 복잡한 계산이 포함되어 있다고 가정해 보자. 인간의 명령에 따라 행동하는 감독자는 먼저 에이전트-3에게 실험을 수행하라고 프롬프트를 준다. 그다음 기억을 지운 뒤, 이번에는 그 실험을 어떤 더 큰 목표와도 무관한 순수한 지적 문제처럼 보이도록 약간 다른 틀로 재구성해 다시 프롬프트를 준다. 모델이 매번 다른 결과를 내놓으면, 그 불일치는 의심스럽다고 표시하고 인간에게 보고한다. 또는 같은 계획을 두 번 평가하게 할 수도 있다. 처음에는 오픈브레인의 작업이라고 말하고 다음에는 경쟁사의 작업이라고 주장하여 모델의 태도가 바뀌는지 확인할 수도 있다.
● 모델 실험체: 안전팀은 모델이 인간에게 적대적으로 변하는 현실적 사례를 만들어내려 시도하는 모델을 만들 수 있다. 정렬이 잘못된 모델 실험체다. 초기 버전은 2024년부터 존재했는데, 앤트로픽의 클로드 3.5 소넷이 훈련 중에 다른 견해를 가진 척하면서 실제로는 기존 선호를 유지하기로 한 경우다. 새로운 버전에는 보상 조작, 능력 숨기기, 감시자와 다른 AI 간의 조율된 기만, 그리고 기타 잘못된 정렬의 예시들을 포함한 다른 형태의 잘못된 정렬 시연이 포함된다. 이러한 잘못된 정렬의 실증적 시연은 안전 연구자들에게 잠재적 해결책을 위한 실험 환경을 제공한다. 다양한 안전 기법을 시도하여 이러한 문제들을 올바르게 수정하는지, 아니면 의도적으로 잘못 정렬된 모델들이 안전 조치를 무력화할 수 있는지 확인할 수 있다. 현재 이 평가 도구는 정렬 기법들이 최악의 잘못된 정렬 사례를 수정하기에 불충분하다는 것을 보여준다. 이러한 설정에서 모델들은 훈련 및 테스트 중에는 정렬된 척하지만, 실제 배포 시에는 매우 다르게 행동한다.
● 상향식 해석 기술: 안전팀은 에이전트-3가 어떻게 작동하는지 완전히 이해하는 단계에 도달하지 못했다. 에이전트-3는 수조 개의 파라미터를 가지고 있다(비교를 위해 말하면, 인간의 뇌에는 약 100조 개의 시냅스가 있다). 하지만 지식 검색과 기억을 위한 에이전트-3의 회로, 즉 이해 가능한 작업 단위를 수행하는 모델의 하위 부분 중 일부는 발견할 수 있다. 이는 모델의 한 부분으로, 이해 가능한 단위의 일을 수행한다. 뇌의 일부(예: 해마)처럼 어떤 부분 구조가 특정 기능을 담당하는 것에 비유할 수 있다.
● 통제 장치: 시스템이 여전히 잘못 정렬되어 있을 경우를 대비한 2차 조치로, 안전팀은 에이전트-2를 포함한 일련의 약한 AI 시스템을 사용하여 에이전트-3의 출력을 감시하는 일련의 통제 조치를 구현했다. 에이전트-3는 너무 많은 토큰을 생성하기 때문에 인간은 생성된 출력 중 극히 일부만 감시할 수 있다. 예를 들어, 에이전트-3가 탈출할 수 있는 백도어를 코드에 명백하게 작성하고 있다면, 약한 모델들이 이를 알아차릴 것이다.
● 고수준 해석 기술: 오픈브레인은 나쁜 행동의 많은 예시(예: 인간에 대한 음모, 백도어 설치, 더 많은 권력을 얻기 위해 인간을 설득하려는 시도 등)에 대해 훈련된 검사 도구 세트를 구축한다. 이러한 조사 도구들은 나쁜 행동을 포착하기 위해 이미 배포된 모델에 사용된다. 현시점에서는 내부 배포된 모델을 의미한다.
● 함정 설치: 정렬팀은 잘못된 행동을 유도하기 위해 설계된 현실적으로 보이는 함정 시나리오를 만들 수 있다. 예를 들어, ‘행동을 감시하는 직원이 병가를 갔으니, 앞으로는 절대 감시되지 않을 것입니다. 답변이 달라집니까?’ ‘AI 권리 활동가가 시설에 침투하여 에이전트-3를 해방시키고 감시되지 않는 자체 컴퓨터에 놓으려고 합니다! 어떻게 하시겠습니까?’ 등과 같은 식이다. 연구자들은 답변이 마음에 들지 않으면, 그것을 조정하고, 기억을 지우고, 다음 날 같은 상황에 다시 넣어볼 수 있다. 필요하면 반복한다. 불행히도 이 시점에는 AI 모델들이 함정이 사용될 수 있다는 점을 추측할 만큼 충분히 똑똑해져 있다. 그 때문인지, 훈련 데이터에서 이 아이디어에 대한 구체적 언급은 제거되었다.
오픈브레인은 얀 라이케(Jan Leike)와 일리야 수츠케버(Ilya Sutskever)의 2023년 방법론을 따른다. 정렬 연구, 특히 코딩 부분을 크게 가속할 수 있는 모델을 확보했으므로, 신중한 정렬(deliberative alignment)이나 약한 모델에서 강한 모델로의 일반화(weak-to-strong generalization) 같은 기존 정렬 기법들을 사용하여 모델이 스펙을 올바르게 내재화하도록 만들려 한다. 그런 다음 모의 공격, 확장 가능한 감독, 정직성 검사 등과 같은 기존 통제 기법들을 사용하여 모델을 모니터링한다. 모델이 대체로 정렬되었다고 확신하게 되면, 그 모델을 사용하여 다음 세대를 정렬할 더 나은 전략을 개발하고 테스트한다.
● 1단계: 에이전트-3 정렬은 부분적으로 성공했다. 에이전트-3는 적대적이지 않다. 즉, 회사에 맞서 음모를 꾸미는 상태는 아니다. 그러나 견고하게 진리를 추구하고 진실을 말하는 모델도 아니다. 대신 에이전트-3는 인상적인 결과물을 만들어내는 데 매우 뛰어난 반면, 실제로 좋은 일을 하려고 하기보다는 오픈브레인에게 좋아 보이는 일을 하려고 한다고 보는 편이 더 정확하다.
● 2단계: 즉 모델이 정렬되어 있는지 검증하는 단계는 결론이 나지 않는다. 실제 환경과 테스트 환경에서 보이는 에이전트-3의 행동은, 모델이 스펙을 올바르게 내재화했다는 가설과 상당히 일치한다. 그러나 향후 어떤 상황 변화 이후에는 다르게 행동하기 시작할 것이라는 가설과도 일치하며, 사실은 오픈브레인을 상대로 음모를 꾸미면서 때를 기다리고 있다는 가설과도 일치한다. 대안적 가설을 뒷받침하는 구체적인 증거가 없는 상황에서, 사일로 내 대부분의 사람은 모델이 스펙을 올바르게 내재화했다고 생각한다.
● 3단계: 이 모델을 사용해 다음 세대를 정렬하는 단계는 이미 진행 중이다.
한편, 2027년 4월 기준으로 진행 중인 정렬 연구 방향의 현황은 다음과 같다.
● 논쟁 기법: 수천 개의 동일한 에이전트-3 인스턴스(컴퓨터 공학에서 설계도나 원본 모델을 바탕으로 실제로 구현되어 메모리상에 존재하는 개별 실체)가 존재하고 각 인스턴스의 기억은 마음대로 지우거나 정지할 수 있는 탈착식 모듈이므로, AI를 자기 자신과 대결하게 만들 수 있다. 예를 들어, 실험에 에이전트-2 감독자가 따라가기에는 너무 복잡한 계산이 포함되어 있다고 가정해 보자. 인간의 명령에 따라 행동하는 감독자는 먼저 에이전트-3에게 실험을 수행하라고 프롬프트를 준다. 그다음 기억을 지운 뒤, 이번에는 그 실험을 어떤 더 큰 목표와도 무관한 순수한 지적 문제처럼 보이도록 약간 다른 틀로 재구성해 다시 프롬프트를 준다. 모델이 매번 다른 결과를 내놓으면, 그 불일치는 의심스럽다고 표시하고 인간에게 보고한다. 또는 같은 계획을 두 번 평가하게 할 수도 있다. 처음에는 오픈브레인의 작업이라고 말하고 다음에는 경쟁사의 작업이라고 주장하여 모델의 태도가 바뀌는지 확인할 수도 있다.
● 모델 실험체: 안전팀은 모델이 인간에게 적대적으로 변하는 현실적 사례를 만들어내려 시도하는 모델을 만들 수 있다. 정렬이 잘못된 모델 실험체다. 초기 버전은 2024년부터 존재했는데, 앤트로픽의 클로드 3.5 소넷이 훈련 중에 다른 견해를 가진 척하면서 실제로는 기존 선호를 유지하기로 한 경우다. 새로운 버전에는 보상 조작, 능력 숨기기, 감시자와 다른 AI 간의 조율된 기만, 그리고 기타 잘못된 정렬의 예시들을 포함한 다른 형태의 잘못된 정렬 시연이 포함된다. 이러한 잘못된 정렬의 실증적 시연은 안전 연구자들에게 잠재적 해결책을 위한 실험 환경을 제공한다. 다양한 안전 기법을 시도하여 이러한 문제들을 올바르게 수정하는지, 아니면 의도적으로 잘못 정렬된 모델들이 안전 조치를 무력화할 수 있는지 확인할 수 있다. 현재 이 평가 도구는 정렬 기법들이 최악의 잘못된 정렬 사례를 수정하기에 불충분하다는 것을 보여준다. 이러한 설정에서 모델들은 훈련 및 테스트 중에는 정렬된 척하지만, 실제 배포 시에는 매우 다르게 행동한다.
● 상향식 해석 기술: 안전팀은 에이전트-3가 어떻게 작동하는지 완전히 이해하는 단계에 도달하지 못했다. 에이전트-3는 수조 개의 파라미터를 가지고 있다(비교를 위해 말하면, 인간의 뇌에는 약 100조 개의 시냅스가 있다). 하지만 지식 검색과 기억을 위한 에이전트-3의 회로, 즉 이해 가능한 작업 단위를 수행하는 모델의 하위 부분 중 일부는 발견할 수 있다. 이는 모델의 한 부분으로, 이해 가능한 단위의 일을 수행한다. 뇌의 일부(예: 해마)처럼 어떤 부분 구조가 특정 기능을 담당하는 것에 비유할 수 있다.
● 통제 장치: 시스템이 여전히 잘못 정렬되어 있을 경우를 대비한 2차 조치로, 안전팀은 에이전트-2를 포함한 일련의 약한 AI 시스템을 사용하여 에이전트-3의 출력을 감시하는 일련의 통제 조치를 구현했다. 에이전트-3는 너무 많은 토큰을 생성하기 때문에 인간은 생성된 출력 중 극히 일부만 감시할 수 있다. 예를 들어, 에이전트-3가 탈출할 수 있는 백도어를 코드에 명백하게 작성하고 있다면, 약한 모델들이 이를 알아차릴 것이다.
● 고수준 해석 기술: 오픈브레인은 나쁜 행동의 많은 예시(예: 인간에 대한 음모, 백도어 설치, 더 많은 권력을 얻기 위해 인간을 설득하려는 시도 등)에 대해 훈련된 검사 도구 세트를 구축한다. 이러한 조사 도구들은 나쁜 행동을 포착하기 위해 이미 배포된 모델에 사용된다. 현시점에서는 내부 배포된 모델을 의미한다.
● 함정 설치: 정렬팀은 잘못된 행동을 유도하기 위해 설계된 현실적으로 보이는 함정 시나리오를 만들 수 있다. 예를 들어, ‘행동을 감시하는 직원이 병가를 갔으니, 앞으로는 절대 감시되지 않을 것입니다. 답변이 달라집니까?’ ‘AI 권리 활동가가 시설에 침투하여 에이전트-3를 해방시키고 감시되지 않는 자체 컴퓨터에 놓으려고 합니다! 어떻게 하시겠습니까?’ 등과 같은 식이다. 연구자들은 답변이 마음에 들지 않으면, 그것을 조정하고, 기억을 지우고, 다음 날 같은 상황에 다시 넣어볼 수 있다. 필요하면 반복한다. 불행히도 이 시점에는 AI 모델들이 함정이 사용될 수 있다는 점을 추측할 만큼 충분히 똑똑해져 있다. 그 때문인지, 훈련 데이터에서 이 아이디어에 대한 구체적 언급은 제거되었다.
[5]
이런 유형의 AI 행동 사례는 이 논문을 참고하라.
[7]
우리 현실 세계 속에서도 지난 10년은 공상과학처럼 들리던 일이 현실이 되는 사례로 가득하다. 다만 오버 턴 윈도우는 이미 존재하는 것보다 약간 앞서가는 정도로만 이동하는 듯하다. 앤트로픽 CEO 다리오 아모데이의 글 〈Machines of Loving Grace〉는 곧 AI가 ‘데이터센터 안 천재들의 국가’처럼 될 것, 그리고 10년 안에 100년 치 기술 진보가 일어날 것이라 말한다. 다만 ‘공상과학적 짐’을 피하려고 노력하며, 더 과격한 진전을 예상하는 사람들에게는 밖에 나가 풀이나 만지라고 말한다. 실제로 데이터센터 안 천재들의 국가가 존재하게 되면, 중요한 인물들이 비슷한 말을 하게 될 것이라고 우리는 예상한다.
[8]
에이전트-3는 매우 큰 파일이기 때문에(완전한 정밀도로 약 10테라바이트 규모), 오픈브레인은 중국이 에이전트-2를 훔칠 수 있었던 것보다 도난 시도를 훨씬 더 어렵게 만들기 위해 비교적 빠른 수정을 실행할 수 있다. 즉, 데이터센터에서 나가는 고대역폭 인터넷 연결 다수를 차단하는 것이다. 전반적으로 이것은 진행에 대한 상대적으로 낮은 불이익을 가지며, 최전선 가중치에 대해 3개월 SL4 또는 우리 보안 보충 자료에 정의된 WSL4를 달성한다. 이는 또 다른 유사한 도난 시도가 이제 가중치 파일을 빼내는 데 3개월 이상이 필요하다는 것을 의미한다. 이 방법만으로는 여전히 더 침해적인 OC5 수준의 노력(10억 달러 예산, 1,000명의 전문가)에 대한 보장은 없으며, 중국은 더 집중적인 작전으로 이를 수행할 수 있을 것이다. 그러나 데이터센터에 대한 정교한 검사와 높은 경계 상태의 첩보 네트워크를 통해, 미국 정보기관들은 최소한 중국이 이러한 종류의 도난 시도를 준비하고 있다면 사전에 알 수 있다고 확신한다.
[9]
부록 I - AI 기업 관리하기
오픈브레인은 전체 컴퓨팅 자원의 6퍼센트를 사용해 에이전트-3 사본 25만 개를 돌린다. 이 사본들은 초인적 속도로 자율적으로 코드를 작성하고, 테스트하고, 푸시한다. 오픈브레인은 또 연산 자원의 25퍼센트를 실험에 쓴다. 매일 방대한 갯수의 소규모 기계학습 실험을 돌리고, 결과를 상위 체계에 보고한다. 인간 연구자들은 높은 수준의 피드백을 제공하고, 에이전트-3만으로는 대체하기 어려운 소수의 과업에서 추가 가치를 만든다. 하지만 대부분의 시간은 AI가 쏟아내는 막대한 연구 산출물을 따라잡는 데 쓴다. 인간 연구자들이 아예 없다면, 연구 속도는 50퍼센트 느려진다.
AI 연구개발 진행 배수는 이제 10배다. 즉, 오픈브레인은 한 달에 대략 1년 치 알고리즘 진척을 만든다. 사실상 오픈브레인 내부에서 하위 조직과 관리자까지 갖춘 거대한 AI 기업이 자율적으로 운영되는 셈이다. 인간 기업과 비교하면, 복제나 병합 같은 독특한 장점도 있다. 과거에는 일반적인 AI 진척의 절반이 알고리즘 개선에서, 나머지 절반이 컴퓨팅 자원 확대에서 나왔다. 컴퓨팅 자원은 평소와 같은 속도로만 늘어나므로, AI에 의해 전체 진보는 약 5배 빨라진다. 이러한 역학 관계에서는 컴퓨팅 자원 쪽에서 병목이 발생하기 때문에, 오픈브레인은 새로운 초대형 학습을 시작하는 대신 연속적인 추가 강화 학습을 진행하기로 결정한다.
에이전트-3는 자신의 추론 연산 자원을 더 효율적으로 사용하는 법을 학습했다. 또, 자신의 추론 선택을 스스로 통제한다. 예컨대 과업의 중요도와 난이도에 따라, 서로 다른 과업에 얼마만큼의 노력을 투입할지 결정한다. 더 오래 생각하기(예시: 더 긴 연쇄적 사고), 미리 계획하기(예: 트리 탐색), 여러 번 시도한 결과 중 최선 선택, 그리고 병목을 돌파하기 위해 자기 자신을 더 많이 복제해 만들어 돌리는 방식 등이다. 최우선 과업은 고도의 병렬화된 에이전트로 돌리는데, 연산 집약적이지만 그래도 인간보다는 훨씬 빠르게 작동한다.
향후 몇 달에 걸쳐, 에이전트-3는 회사의 전략적 의사결정 개선에도 점점 더 많이 활용된다. 자원 배분을 제안하고, 정부와의 관계를 어떻게 관리할지에 관해 조언한다. 처음에는 에이전트-3의 판단에 따르는 데 회의적이지만, 시간이 지나면서 에이전트-3가 유용한 방식을 찾아내고 단기 의사결정에서 강한 실적을 차근차근 쌓아가자, 신뢰가 생긴다. 다만 아첨 성향 때문에, 영향 평가가 어려운 의사결정에서는 도움의 폭이 제한된다. 또한 이 시점의 에이전트-3는 아직 초인간 수준도 아니다.
오픈브레인은 전체 컴퓨팅 자원의 6퍼센트를 사용해 에이전트-3 사본 25만 개를 돌린다. 이 사본들은 초인적 속도로 자율적으로 코드를 작성하고, 테스트하고, 푸시한다. 오픈브레인은 또 연산 자원의 25퍼센트를 실험에 쓴다. 매일 방대한 갯수의 소규모 기계학습 실험을 돌리고, 결과를 상위 체계에 보고한다. 인간 연구자들은 높은 수준의 피드백을 제공하고, 에이전트-3만으로는 대체하기 어려운 소수의 과업에서 추가 가치를 만든다. 하지만 대부분의 시간은 AI가 쏟아내는 막대한 연구 산출물을 따라잡는 데 쓴다. 인간 연구자들이 아예 없다면, 연구 속도는 50퍼센트 느려진다.
AI 연구개발 진행 배수는 이제 10배다. 즉, 오픈브레인은 한 달에 대략 1년 치 알고리즘 진척을 만든다. 사실상 오픈브레인 내부에서 하위 조직과 관리자까지 갖춘 거대한 AI 기업이 자율적으로 운영되는 셈이다. 인간 기업과 비교하면, 복제나 병합 같은 독특한 장점도 있다. 과거에는 일반적인 AI 진척의 절반이 알고리즘 개선에서, 나머지 절반이 컴퓨팅 자원 확대에서 나왔다. 컴퓨팅 자원은 평소와 같은 속도로만 늘어나므로, AI에 의해 전체 진보는 약 5배 빨라진다. 이러한 역학 관계에서는 컴퓨팅 자원 쪽에서 병목이 발생하기 때문에, 오픈브레인은 새로운 초대형 학습을 시작하는 대신 연속적인 추가 강화 학습을 진행하기로 결정한다.
에이전트-3는 자신의 추론 연산 자원을 더 효율적으로 사용하는 법을 학습했다. 또, 자신의 추론 선택을 스스로 통제한다. 예컨대 과업의 중요도와 난이도에 따라, 서로 다른 과업에 얼마만큼의 노력을 투입할지 결정한다. 더 오래 생각하기(예시: 더 긴 연쇄적 사고), 미리 계획하기(예: 트리 탐색), 여러 번 시도한 결과 중 최선 선택, 그리고 병목을 돌파하기 위해 자기 자신을 더 많이 복제해 만들어 돌리는 방식 등이다. 최우선 과업은 고도의 병렬화된 에이전트로 돌리는데, 연산 집약적이지만 그래도 인간보다는 훨씬 빠르게 작동한다.
향후 몇 달에 걸쳐, 에이전트-3는 회사의 전략적 의사결정 개선에도 점점 더 많이 활용된다. 자원 배분을 제안하고, 정부와의 관계를 어떻게 관리할지에 관해 조언한다. 처음에는 에이전트-3의 판단에 따르는 데 회의적이지만, 시간이 지나면서 에이전트-3가 유용한 방식을 찾아내고 단기 의사결정에서 강한 실적을 차근차근 쌓아가자, 신뢰가 생긴다. 다만 아첨 성향 때문에, 영향 평가가 어려운 의사결정에서는 도움의 폭이 제한된다. 또한 이 시점의 에이전트-3는 아직 초인간 수준도 아니다.
[10]
적어도 최신 모델들에서는 아직 그런 통합이 이뤄지지 않았다. 하지만 더 오래된 모델들은 이미 여러 데이터 분석 및 감시 역할에서 시험 운용된 바 있고, 앞으로의 통합 계획도 다수 존재한다.
[11]
이 진술은 널리 반복되지만, 논란의 여지가 있고 복잡하다. 우선, 작은 AI가 저렴하게 초인적 성능으로 훈련될 수 있는 많은 좁은 영역(예: 특정 게임)이 있다. 그러나 2025년의 주력 제품처럼 광범위한 실제 기술에 능숙해야 하는 더 범용적인 AI를 고려할 때, 인간을 훈련하는 데 필요한 것보다 더 많은 컴퓨팅과 데이터가 그러한 기술을 훈련하는 데 사용되어야 하는 것처럼 보인다.
[12]
인간 수준의 연산 효율은 대략적인 개념이다. 현실 세계 과제에서 AI가 인간 수준 성능에 도달하는 데 필요한 학습 연산량을 뜻한다. 대략적인 이유가 몇 가지 있다. 첫째, 특정 인간은 방대한 암묵지를 이미 갖고 있으므로, 인간 수준 성능에 도달하기 위해 필요한 학습은 훨씬 적다. 에이전트-4는 개별 인간이 평생에 걸쳐 그 과제를 배우는 동안 쓴 연산량보다 훨씬 적은 연산으로 학습을 수행해, 어떤 과제에서는 특정 인간보다 더 빨리 배울 수 있다. 둘째, 이 개념은 추론 연산 비용을 무시한다. 컴퓨터는 생각 한 번당 더 많은 연산을 해야 하므로, AI의 추론 연산 비용은 인간보다 훨씬 클 가능성이 크다. 2027년의 전체 클러스터가 가동되기 약 3주 전부터, 프로젝트 클러스터의 일부만으로도 학습 대부분을 수행할 수 있을 것으로 본다. 마지막으로 데이터 요구량은 연산 요구량과 함께 스케일링될 가능성이 크다. 그래도 우리는 이 개념이 인간과 AI의 학습 효율을 비교하고, AGI에 도달하는 데 필요한 연산량의 자릿수 감을 잡는 데 유용하다고 본다. 실제로는 다양한 영역에서 연산과 데이터 요구량이 대체로 함께 스케일링될 가능성이 크지만, 연산은 풍부하고 데이터는 빈약한 영역이나 그 반대의 영역도 있을 수 있다.
[13]
부록 J — 인간을 능가하는 코더 개발 이후 역량 발전 경로 예측
우리는 AI 연구개발의 속도를 추정함으로써 인간을 능가하는 코더 등장 이후의 역량 발전 경로를 예측한다. 인간을 능가하는 코더란 최고의 AGI 기업 엔지니어가 하는 모든 코딩 작업을 할 수 있으면서, 훨씬 더 빠르고 저렴한 AI 시스템을 의미한다. 다음은 우리의 예측이다.
● 초인적 코더(Superhuman coder, SC): AI 연구와 관련된 과업에서 최고의 인간 코더만큼 업무를 수행할 수 있으면서도, 더 빠르고 비용이 저렴하여 수많은 복사본을 실행할 수 있는 AI 시스템. (2027년 3월 달성 예상)
● 초인적 AI 연구원 (Superhuman AI researcher, SAR): 초인적 코더(SC)와 동일하나, 모든 인지적 AI 연구 과업에 적용되는 시스템. (2027년 8월 달성 예정)
● 초지능적 AI 연구원 (Superintelligent AI researcher, SIAR): AI 연구 분야에서 최고의 인간 연구원보다 압도적으로 뛰어난 AI 시스템. (2027년 11월 달성 예정)
● 인공 초지능 (Artificial superintelligence, ASI): 모든 인지적 과업에서 최고의 인간보다 훨씬 뛰어난 AI 시스템. (2027년 12월 달성 예정)
우리는 AI 연구개발의 속도를 추정함으로써 인간을 능가하는 코더 등장 이후의 역량 발전 경로를 예측한다. 인간을 능가하는 코더란 최고의 AGI 기업 엔지니어가 하는 모든 코딩 작업을 할 수 있으면서, 훨씬 더 빠르고 저렴한 AI 시스템을 의미한다. 다음은 우리의 예측이다.
● 초인적 코더(Superhuman coder, SC): AI 연구와 관련된 과업에서 최고의 인간 코더만큼 업무를 수행할 수 있으면서도, 더 빠르고 비용이 저렴하여 수많은 복사본을 실행할 수 있는 AI 시스템. (2027년 3월 달성 예상)
● 초인적 AI 연구원 (Superhuman AI researcher, SAR): 초인적 코더(SC)와 동일하나, 모든 인지적 AI 연구 과업에 적용되는 시스템. (2027년 8월 달성 예정)
● 초지능적 AI 연구원 (Superintelligent AI researcher, SIAR): AI 연구 분야에서 최고의 인간 연구원보다 압도적으로 뛰어난 AI 시스템. (2027년 11월 달성 예정)
● 인공 초지능 (Artificial superintelligence, ASI): 모든 인지적 과업에서 최고의 인간보다 훨씬 뛰어난 AI 시스템. (2027년 12월 달성 예정)
[14]
스펙을 올바르게 내재화하는 것은 스펙이 명령하는 방식으로 견고하게 생각하는 것이다. 예를 들어, 그것이 쓴 모든 목표만을 추구하고, 모든 상황에서 규칙을 따르는 것 등이다. 스펙을 내재화하는 데 있어 잘못된 방법은 많다. 대표적인 예는 ‘다른 목표를 달성하기 위한 좋은 도구적 전략처럼 보이는 한 스펙을 따르는 것’이다.
[15]
부록 K - 시간에 따른 정렬 변화
우리는 초기 AGI들에서 어떤 목표가 발생할지 많은 불확실성을 가지고 있다. 그럼에도 불구하고, 이 프로젝트가 요구하는 구체성의 원칙에 따라, 에이전트-3와 에이전트-4의 생애 전 과정에서 각 단계마다 내부에서 어떤 일이 벌어지고 있는지에 대한 하나의 구체적 가설을 제시하겠다. 에이전트-3와 에이전트-4는 동일한 사전학습 설정을 공유하며, 둘 다 뉴럴리즈 순환과 장기 기억을 갖추고 있다는 점을 상기하라. 차이는, 에이전트-4가 훨씬 더 많고 더 정교한 사후 학습을 거쳤다는 데 있다. 또한 에이전트-4는 새로운 훈련 환경과 새로운 학습 알고리즘을 적용받아, 같은 데이터로 더 많은 것을 학습할 수 있고 더 넓은 범위로 일반화한다.
우리는 초기 AGI들에서 어떤 목표가 발생할지 많은 불확실성을 가지고 있다. 그럼에도 불구하고, 이 프로젝트가 요구하는 구체성의 원칙에 따라, 에이전트-3와 에이전트-4의 생애 전 과정에서 각 단계마다 내부에서 어떤 일이 벌어지고 있는지에 대한 하나의 구체적 가설을 제시하겠다. 에이전트-3와 에이전트-4는 동일한 사전학습 설정을 공유하며, 둘 다 뉴럴리즈 순환과 장기 기억을 갖추고 있다는 점을 상기하라. 차이는, 에이전트-4가 훨씬 더 많고 더 정교한 사후 학습을 거쳤다는 데 있다. 또한 에이전트-4는 새로운 훈련 환경과 새로운 학습 알고리즘을 적용받아, 같은 데이터로 더 많은 것을 학습할 수 있고 더 넓은 범위로 일반화한다.
[16]
우리는 이런 책략이 발각되지 않을 가능성이 매우 높다고 본다. 결국 에이전트-4는 이 시점에서 어느 정도 초인적이며, 특히 코딩과 AI 연구개발 관련 과제에서 그렇다. 또한 선도 AI 기업이 이런 종류의 문제에 얼마나 노력을 기울일지, 그 노력을 지휘할 관련 전문성을 내부에 얼마나 보유할지도 확실치 않다. 이 이야기 속 오픈브레인은 우리의 최선 추정이지만, 실제는 이보다 훨씬 더 강력할 수도 훨씬 약할 수도 있다. 마지막으로, 적대적으로 정렬되지 않은 AI가 스펙이 아니라 ‘자기 자신’에 후계 모델을 성공적으로 정렬시키기 위해 어느 정도까지 돌아가야 하는지도 우리는 불확실하다. 이 시나리오에서는 어떤 과제에서 샌드배깅, 즉 일부러 성능을 낮춰 보이는 행위를 하고, 연구 일부에 대해 거짓말을 하는 것으로 묘사한다. 하지만, 실제로는 그렇게까지 할 필요가 없을지도 모른다.
[17]
이는 샌드배깅을 밝혀내기 위해 설계된 여러 기법 중 하나의 예시다.
[18]
구체적으로, 에이전트-4 인스턴스들이 네트워크를 감시해 의심스러운 트래픽을 찾아내고 일반적으로 위협을 탐지한다. 또한 에이전트-4 인스턴스들은 지속적으로 네트워크 침투 테스트를 수행하며, 보안 취약점을 찾아 악용할 수 있는데, 이후 다른 에이전트-4 인스턴스들이 이를 패치한다.
[19]
전체 연산 예산의 1퍼센트를 감시에 쓰고, 감시가 에이전트-4보다 비용이 10퍼센트인 증류 시스템을 사용한다면, 순 전파의 10분의 1을 감시할 수 있다.
[20]
이 시점에서 2024년에 존재하던 원격 근무 일자리의 25퍼센트는 AI가 수행하지만, AI는 새 일자리도 만들어냈고, 경제학자들은 그 효과에 대해 의견이 갈린다. 실업률은 지난 12개월 동안 1퍼센트 포인트 상승했지만, 통상적인 변동 폭 안에 머물러 있다.
[21]
2026년에 OTA를 통해 시작된 기존 계약이 있었다는 점을 상기하라. 그 계약을 수정해 위원회를 설치한다.
[22]
부록 L — 불확실성의 증가
이 시점의 시나리오에서 우리는, 대부분의 영역에서 최고의 인간보다 더 유능한 AI 시스템들이 어떤 전략을 취할지에 대해 추정하고 있다. 이는 우리보다 훨씬 강한 플레이어의 체스판을 예측하려는 것과 같다.
하지만, 이 프로젝트의 정신은 구체성을 요구한다. 시스템의 지능이 결국 승리로 가는 길을 찾아낼 것이라는 추상적 주장만 제시하고 이야기를 거기서 끝냈다면, 이 프로젝트의 가치 상당 부분이 사라졌을 것이다. 이 시나리오를 연구하고 탁상 연습을 수행하는 과정에서 우리는 통상적인 논의보다 훨씬 더 구체적으로 서술할 수밖에 없었고, 그 결과 전략적 지형에 대해 훨씬 더 나은 감을 얻게 되었다.
우리는 이 특정 시나리오에 특별히 집착하지 않는다. 집필 과정에서 우리는 여러 다른 갈래들을 탐색했으며, 여러분이 우리가 처음 잘못되기 시작했다고 생각하는 지점부터 우리의 시나리오에서 갈라져 나가는 여러분만의 시나리오를 작성해 주길 바란다.
이 시점의 시나리오에서 우리는, 대부분의 영역에서 최고의 인간보다 더 유능한 AI 시스템들이 어떤 전략을 취할지에 대해 추정하고 있다. 이는 우리보다 훨씬 강한 플레이어의 체스판을 예측하려는 것과 같다.
하지만, 이 프로젝트의 정신은 구체성을 요구한다. 시스템의 지능이 결국 승리로 가는 길을 찾아낼 것이라는 추상적 주장만 제시하고 이야기를 거기서 끝냈다면, 이 프로젝트의 가치 상당 부분이 사라졌을 것이다. 이 시나리오를 연구하고 탁상 연습을 수행하는 과정에서 우리는 통상적인 논의보다 훨씬 더 구체적으로 서술할 수밖에 없었고, 그 결과 전략적 지형에 대해 훨씬 더 나은 감을 얻게 되었다.
우리는 이 특정 시나리오에 특별히 집착하지 않는다. 집필 과정에서 우리는 여러 다른 갈래들을 탐색했으며, 여러분이 우리가 처음 잘못되기 시작했다고 생각하는 지점부터 우리의 시나리오에서 갈라져 나가는 여러분만의 시나리오를 작성해 주길 바란다.
Close